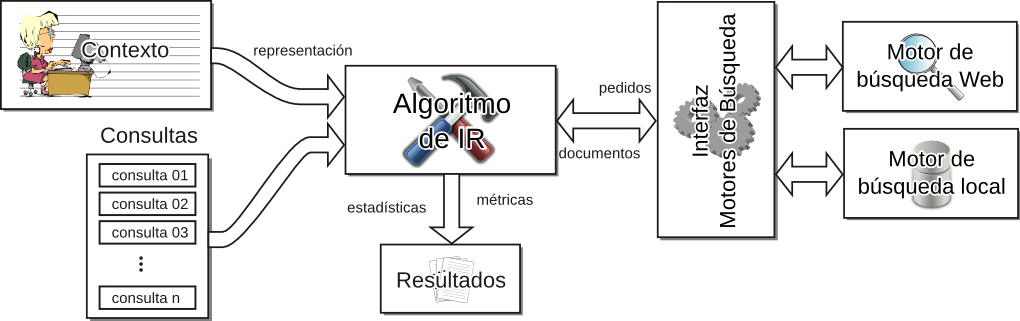
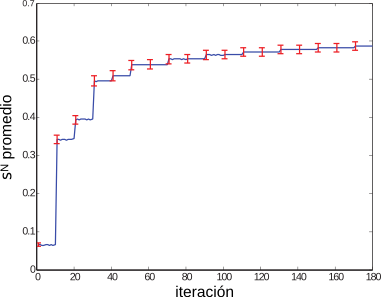
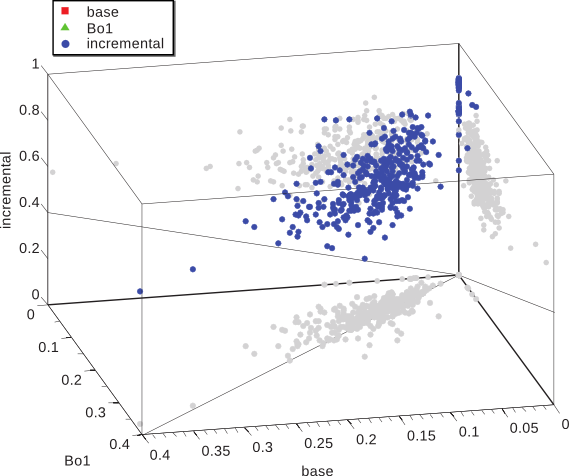
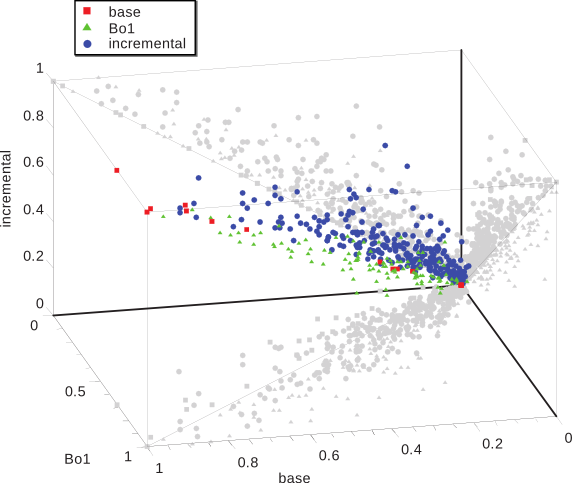
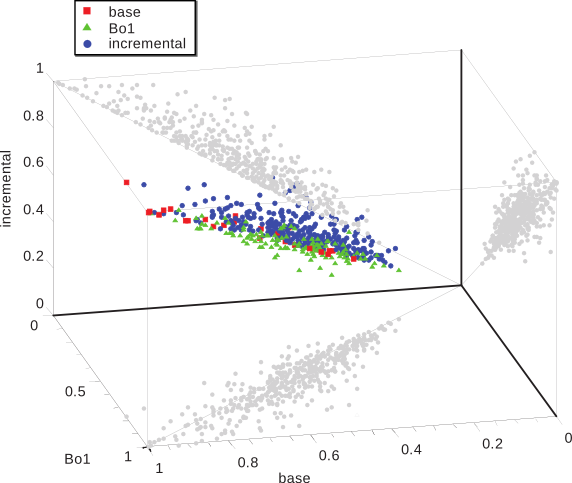
Caracterización Formal y Análisis Empírico de Mecanismos Incrementales de Bísqueda basados en ContextoTesis Doctoral en Ciencias de la Computación - Universidad Nacional del Sur por Carlos M. Lorenzetti Plataforma de evaluaciónEl método descripto en el capítulo anterior fue implementado en el contexto de una plataforma general de IR. Esta se desarrolló con el propósito de proponer y evaluar nuevos algoritmos en el área de IR. El objetivo final es publicar la plataforma bajo una licencia de Código Abierto, de modo que otros grupos de investigación puedan realizar comparaciones y/o mejoras sobre los algoritmos implementados en la misma. Los resultados de las evaluaciones del algoritmo incremental presentado en el capítulo anterior y de otros algoritmos serán mostrados a continuación. EstructuraLa plataforma incluye actualmente una colección local de documentos que fueron indexados con la plataforma de código abierto Terrier, desarrollada por la Universidad de Glasgow. El acceso a este índice se realiza a través de una interfaz que es capaz de aceptar otros tipos de índices e incluso, motores de búsqueda web. En un comienzo, se implementó una interfaz para el servicio web SOAP de Google, que luego fuera reemplazado por la empresa por una API AJAX. La utilización del servicio web permitió el desarrollo de las primeras versiones de los algoritmos presentados en esta tesis. Finalmente se optó por un índice local de documentos web debido a las limitaciones que se encontraron en cuanto a los tiempos de ejecución de los algoritmos y al límite impuesto por Google a la cantidad de consultas que se podían realizar por día. Una representación esquemática de la Plataforma de Evaluación se muestra en la Figura 5-1. Como se puede observar existe una primera parte que se encarga de la representación de las consultas. Estas pueden ingresarse como un conjunto o como un documento, a partir del cual el sistema generará las consultas necesarias. Por otro lado, la plataforma ofrece una interfaz de comunicación con los distintos motores de búsqueda. Como se dijo más arriba, una de las posibilidades es contar con un motor de búsqueda web. También existe un componente dedicado al cálculo de las métricas que guiarán los algoritmos de búsqueda y que también servirán para su evaluación. A continuación se explicarán con más detalles los componentes de la plataforma. Generación de consultasEste componente del sistema se encarga del proceso de generación de las consultas que iniciarán o que utilizarán los algoritmos que se evaluarán con la plataforma. Los algoritmos evaluados y propuestos en esta tesis caen en la categoría algoritmos de recuperación basada en contexto (Sección 4.2), por lo que en todos los casos se cuenta con el contexto del usuario. La generación de consultas puede llevarse a cabo con distintas técnicas. La primera es de forma aleatoria, en donde se seleccionan al azar palabras del contexto del usuario, todas con la misma probabilidad, y es la que se utilizó en [CLMB08] y en [CLMB10]. Otra técnica es el mecanismo de selección por ruleta, en donde la probabilidad de selección de un término está dada por el peso que tiene asignado. Esto provoca una exploración no determinística del espacio de términos que favorece a los más aptos. Este método fue el que se utilizó en [LM09]. Motores de búsquedaEste componente del sistema se encarga de realizar los pedidos de información a los distintos motores de búsqueda con los que cuenta la plataforma. También lleva a cabo la tarea de preprocesar y convertir los resultados a un formato uniforme a todos los motores. Uno de los motores de búsqueda con los que el sistema se comunica es un motor web, en particular se implementó la comunicación con el servicio de búsqueda web de Google. Una forma de acceder al motor de búsqueda web Google es hacer uso de su formulario web y luego aplicar un analizador sintáctico al código HTML que obtenemos. Esta técnica se conoce en inglés como web scraping y no es recomendada por la compañía, pudiendo dar lugar a que filtren el acceso de la computadora que origina los pedidos. Para evitar este tipo de prácticas y para favorecer la investigación sobre los recursos indexados por su buscador, desarrollaron un servicio web SOAP que permitía hacer uso del motor de búsqueda. Este servicio tenía una limitación importante para su uso en cuanto a que imponía un límite máximo a la cantidad de consultas diarias (1000 en un principio); por otra parte, no se garantizaba que los servidores que atendían los pedidos estuvieran todos actualizados con la misma versión del índice, lo que provocó dificultades a la hora de repetir los experimentos. Hoy en día este servicio sigue vigente pero no tiene más soporte. En su lugar existe una API AJAX más orientada a su uso en páginas web. El formato de la consulta del servicio web es similar al formato de la consulta que se ingresa por medio del formulario web, excepto que la cantidad máxima de palabras estaba limitada a 10 (luego ampliada a 32). Los resultados devueltos por el servicio web incluyen, entre otros datos, el URL de cada página y un pequeño fragmento del documento. Otro de los motores de búsqueda que se utilizan es la plataforma de recuperación de información Terrier [OAP+06]. Esta plataforma implementa varios algoritmos del estado del arte en el área de IR y ofrece técnicas eficientes y efectivas en una forma modular y extensible. El sistema incluye modelos de recuperación basados en la Divergencia de la Aleatoriedad, que es un modelo de teoría de la información para expansión de consultas y ordenamiento de documentos (un ejemplo se presentó en la Subsección 2.2.2). También incluye una gran variedad de modelos, como algunas variantes del esquema clásico TF-IDF y el método de modelado de lenguaje basado en la fórmula de ordenamiento estadístico BM25 [RW94]. En esta tesis se utilizó principalmente el componente de indexación de Terrier para crear una colección local de documentos. Terrier ofrece varias APIs para indexación y consulta que fueron adaptadas para su uso en la plataforma propuesta. Al igual que otras plataformas de código abierto disponibles, incluye analizadores sintácticos para indexar documentos en formato de texto plano, HTML, PDF y otros, así como también varios algoritmos de stemming. Otro componente utilizado de esa plataforma fue el de recuperación, el cual admite una serie de operadores en el formato de las consultas, como los más comunes de inclusión y exclusión de términos, pero también permite la asignación de pesos a cada término de la consulta, la expansión de consultas y la búsqueda de términos en determinados campos de un documento. Colección local de documentosComo se mencionó anteriormente, la plataforma desarrollada para el soporte y la evaluación de los algoritmos propuestos en esta tesis incluye una colección local de documentos, indexados con el propósito de acelerar el proceso de evaluación de algoritmos, principalmente frente a las limitaciones de velocidad que presenta un servicio web. Otras limitaciones que se superaron con el uso de una colección local se mencionarán en la sección siguiente. Como se mencionó en la Sección 3.2, al crear una colección de documentos uno de los mayores desafíos es evaluar la relevancia de cada uno de los documentos del índice, entonces al crear la colección se optó por indexar un conjunto de documentos de la ontología ODP. Esto permitió la evaluación de los algoritmos propuestos con métricas que hacen uso de relaciones de similitud semántica (vista en la Sección 2.4) y que se detallarán en la sección siguiente. Para realizar los experimentos se utilizaron $|V|=448$ tópicos del ODP. Fueron elegidos los tópicos que se encuentran en el tercer nivel de la jerarquía. Se impusieron un número de restricciones a esta selección para asegurar la calidad del conjunto de datos. El tamaño de cada tópico seleccionado fue de 100 URLs como mínimo y se limitaron los tópicos a aquellos que pertenecen al lenguaje inglés. Para cada uno de estos tópicos se recuperaron todos sus URLs así como también los pertenecientes a sus subtópicos. Todas las páginas pertenecientes a un tópico o a alguno de sus descendientes se consideraron, a los efectos de las métricas, como el mismo tópico. El número total de páginas resultó ser más de 350 mil. Métricas de evaluaciónCon el objetivo de medir la efectividad que alcanza el sistema, este componente se encarga de calcular distintas métricas sobre los resultados que le entrega el algoritmo en evaluación. Las medidas que pueden aplicarse para guiar al algoritmo son las clásicas del área de IR (como las vistas en la Sección 3.4) u otras nuevas. Como se mencionó en la sección anterior, las evaluaciones comenzaron utilizando un motor de búsqueda web que, como parte de los resultados, devolvía un pequeño fragmento del documento recuperado. Por lo tanto, una de las primeras métricas con las que se evaluaron los algoritmos fue la medida clásica de IR, similitud por coseno (discutida en la Subsección 2.1.2). Por cuestiones de eficiencia, la métrica sólo se utilizó para comparar el contexto del usuario con cada fragmento de los documentos recuperados por el motor de búsqueda. En particular, puede notarse que al utilizar un motor web no es posible calcular otras métricas como la cobertura, dado que no hay una forma de saber de antemano qué páginas pertenecen al conjunto de documentos relevantes para la consulta que se está haciendo. Otro problema que aparece es que, en general, este fragmento contiene porciones del documento cercanas a las palabras de la consulta y, por lo tanto, es muy probable que éstas estén contenidas dentro de ese fragmento. Puede verse que es sencillo alcanzar valores altos de similitud, perjudicando incluso a aquellos documentos que pudieran ser relevantes y que no emplean el mismo vocabulario que el usuario, desfavoreciendo la exploración de material novedoso. Similitud NovedosaEn vista de las consideraciones expuestas arriba, en esta tesis se propone una nueva métrica llamada Similitud Novedosa. La similitud novedosa es una medida de similitud ad hoc que está basada en la Ecuación 2.1 definida en el Capítulo 2. Esta nueva medida descarta los términos que forman parte de la consulta al momento de hacer los cálculos, reduciendo el sesgo introducido por esos términos y favoreciendo la exploración de nuevos documentos. Definición 16 Dado un vector de consulta $\overrightarrow{q}=(w(k_1,q), \dots, w(k_t,q))$ y dos documentos $\overrightarrow{d_j}=(w(k_1,d_j), \dots, w(k_t,d_j))$ y $\overrightarrow{d_k}=(w(k_1,d_k), \dots, w(k_t,d_k))$, representados en el modelo vectorial de acuerdo con la forma enunciada en la Definición 3. Sean $k_i$ con $i \in [1\dots t]$, en donde $t$ es el número total del términos en el sistema, cada uno de los términos que pudieran contener $\overrightarrow{q}$, $\overrightarrow{d_j}$ o $\overrightarrow{d_k}$. Entonces, la similitud novedosa se define como: $$ \begin{align} \mathit{sim}^{N}(q,d_j,d_k) &= \mathit{sim}(\overrightarrow{d_j - q}, \overrightarrow{d_k - q}) \text{,}\\ \end{align} $$La notación $\overrightarrow{d_j - q}$ es la representación del documento $d_j$ con valores nulos en todos los términos correspondientes a la consulta ${q}$. Lo mismo se aplica a $\overrightarrow{d_k - q}$. Por lo tanto: $$ \begin{align} &= \frac{\sum\nolimits_{% \begin{subarray}{l}% i = 1 \\ % \forall {k_i} \notin q% \end{subarray}% }^{t}{w(k_i,d_j) . w(k_i,d_k)}}{\sqrt {\sum\nolimits_{% \begin{subarray}{l}% i = 1 \\ % \forall {k_i} \notin q% \end{subarray}% }^t w(k_i,d_j)^{2}} .\sqrt {\sum\nolimits_{% \begin{subarray}{l}% i = 1 \\ % \forall {k_i} \notin q% \end{subarray}% }^t w(k_i,d_k)^{2}}}\text{.} \end{align} $$Precisión SemánticaOtras métricas que se implementaron dentro de la plataforma de evaluación fueron, la Precisión, la Cobertura y la Precisión a un rango k. Por otro lado, en esta tesis también se propone otra métrica, la Precisión Semántica. De acuerdo a lo visto en el Capítulo 3, la Precisión se define como la porción de documentos recuperados que son relevantes (Ecuación 3.1). Si creamos una función de similitud a partir de esta métrica, $\mathit{sim}_{rel}$, que le asigne un peso de 1 a un documento, $d_j$, si pertenece al conjunto de los documentos relevantes, $R$, y un peso nulo en otro caso, tenemos $$ \begin{align*} \mathit{sim}_{rel}(d_j) = \left\{ {\begin{array}{*{20}l} 1 & \mbox{si }d_j\in {R}\mbox{,}\\ 0 & \mbox{si no.} \\ \end{array}} \right. \end{align*} $$Vemos que esta función es binaria e indica si un documento pertenece al conjunto de documentos relevantes. Luego, recordando que $A$ representa el conjunto de documentos recuperados, la ecuación de Precisión, $P$, puede reescribirse de la siguiente manera: $$ \begin{align*} P = \frac{\sum_{d_j\in A}\mathit{sim}_{rel}(d_j)}{|A|}\text{.} \end{align*} $$El objetivo de los algoritmos desarrollados en esta tesis es encontrar documentos que sean relevantes para el tópico del contexto del usuario, $\mathcal{C}$, por lo tanto, utilizar una métrica de relevancia binaria descarta la posibilidad de recuperar muchos documentos parcialmente relevantes y por lo tanto potencialmente útiles. Entonces, se propone una medida de precisión semántica, basada en las nociones de similitud vista en la Sección 2.4. Definición 17 Sea $\mathfrak{T}(d_j)$ una función que devuelve el tópico al que pertenece un documento. Sea $\mathcal{C}$ el contexto del usuario el cual pertenece a un tópico $\tau_0 = \mathfrak{T} (\mathcal{C})$. Sea $\mathit{sim}^{S}(\tau_1,\tau_2)$ la similitud semántica entre estos dos tópicos, definida en la Ecuación 2.14. La precisión semántica, $P^S$, se define como: $$ \begin{align} P^S&= \frac{\sum_{d_j\in A}\mathit{sim}^{S}(\mathfrak{T}(\mathcal{C}),\mathfrak{T}(d_j))}{|A|}\text{.} \end{align} $$Las métricas de Precisión, Precisión Semántica y Cobertura se utilizaron en conjunto con la colección local de documentos, por lo tanto, la función $\mathfrak{T}(d_j)$ simplemente devuelve el tópico dentro de la ontología ODP al que pertenece $d_j$. Evaluación de los AlgoritmosEn esta sección ilustraremos la aplicación de la plataforma de evaluación propuesta. Con tal fin se presentarán los resultados obtenidos en las evaluaciones del Algoritmo Incremental para el Refinamiento de Consultas propuesto en la Sección 4.5 y otros algoritmos de búsqueda basados en contexto propuestos por el grupo de investigación del autor de la presente tesis, publicados en [Cec10]. En las siguientes dos subsecciones se compararán los métodos propuestos con otros existentes en la literatura. Algoritmos IncrementalesEl objetivo de esta sección es comparar el método propuesto con otros dos métodos. El primero es un método base que genera las consultas directamente del contexto temático y no aplica ningún mecanismo de refinamiento. El segundo método es el Bo1-DFR descripto en la Subsección 2.2.2. Para la creación del contexto inicial $\mathcal{C}$ utilizado en los experimentos, se hizo uso de la descripción que contiene cada tópico en ODP. El algoritmo propuesto se ejecutó en cada tópico por al menos $v=10$ iteraciones, con 10 consultas por iteración y recuperando 10 resultados por consulta. Las listas de descriptores y discriminadores en cada iteración se limitaron a 100 términos cada una. Otros parámetros del método fueron ajustados de la siguiente manera: el número de iteraciones por prueba $u=10$, los coeficientes de conservación y de actualización del poder descriptivo y discriminante durante una prueba $\alpha$=0.5 y $\beta$=0.5, el coeficiente de conservación del peso de los términos en el contexto de un usuario $\gamma$=0.33, los coeficientes de actualización del peso de un término respecto del poder descriptivo y discriminante aprendido en la fase anterior $\zeta$=0.33 y $\xi$=0.33, el nivel de efectividad mínimo esperado durante una prueba $\mu$=0.2 y el nivel de efectividad mínimo esperado durante una fase $\nu$=0.1. Además se utilizó la lista de palabras frecuentes proporcionada con Terrier, se aplicó el algoritmo de stemming de Porter [Por80] en todos los términos y no se aplicaron ninguno de los métodos de expansión de consultas provistos por la plataforma. Se calculó la métrica de similitud novedosa $\mathit{sim}^{N}$ entre el contexto inicial (la descripción del tópico) y los resultados recuperados. La Figura 5-2 muestra la evolución de la similitud novedosa promedio sobre todos los tópicos evaluados. Además, el gráfico muestra las barras de error cada 10 iteraciones (las cuales normalmente coinciden con un cambio de fase). Las mejoras observadas, especialmente durante el primer cambio de fase, proporcionan evidencias de que el algoritmo propuesto puede ayudar a mejorar el vocabulario del tópico. Los diagramas en las Figuras 5-3, 5-4, 5-5 comparan el rendimiento de las consultas para cada método evaluado utilizando similitud novedosa, precisión y precisión semántica. Se tomaron cada uno de los 448 tópicos indexados y se ejecutó el algoritmo incremental con el propósito de recuperar la mayor cantidad de documentos de ese tópico. Cada tópico corresponde a un experimento y está representado en las figuras por un punto. La coordenada vertical del punto (z) corresponde al rendimiento del método incremental, mientras que las otras dos (x e y) corresponden al método base y al método Bo1-DFR. Se puede observar además la proyección de cada punto sobre los planos x-y, x-z e y-z. Sobre el plano x-z, los puntos por encima de la diagonal corresponden a los casos en los que el método incremental es mejor que el base. De la misma manera, para el plano y-z, los puntos por encima de la diagonal corresponden a los casos en los que el método incremental es mejor que el Bo1-DFR. El plano x-y compara el rendimiento del método base con el Bo1-DFR. Puede notarse que se utilizaron distintas marcas para ilustrar los casos en los que un método se comporta mejor que los otros dos. Es interesante notar que para todos los casos evaluados el método incremental fue superior al método base y al método Bo1-DFR en términos de similitud novedosa. Esto muestra la utilidad de evolucionar el vocabulario del contexto para descubrir buenos términos para las consultas. En la métrica precisión, el método incremental fue estrictamente superior a los otros dos métodos en el 66.96% de los tópicos evaluados. El método Bo1-DFR fue el mejor método en el 24.33% de los tópicos y el método base se comportó tan bien como alguno de los otros dos en el 8.70% de los tópicos. Finalmente, en la métrica precisión semántica el método incremental fue estrictamente superior a los otros dos métodos en el 65.18% de los tópicos, Bo1-DFR fue superior en el 27.90% de los tópicos y el método base se comportó tan bien como alguno de los otros dos en el 6.92% de los tópicos. La Figura 5-6 presenta las medias y los intervalos de confianza del rendimiento de los métodos basados en $\mathit{sim}^{N}$, Precisión y $P^S$. Estas tablas de comparación muestran que las mejoras alcanzadas por el método incremental con respecto a los otros métodos son estadísticamente significativas.
Algoritmos Genéticos para la Búsqueda basada en Contextos TemáticosLa selección de buenos términos para una consulta puede verse como un problema de optimización, en donde la función objetivo que quiere optimizarse está relacionada directamente con la efectividad de la consulta para recuperar material relevante. Algunas características de este problema de optimización son:
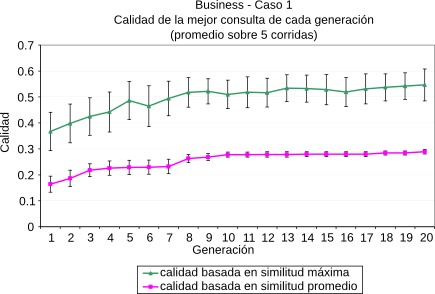
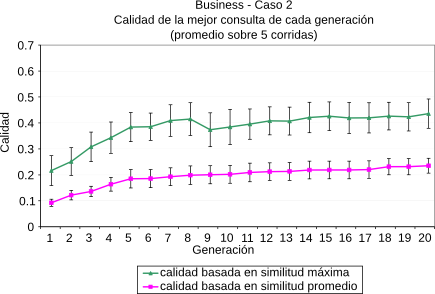
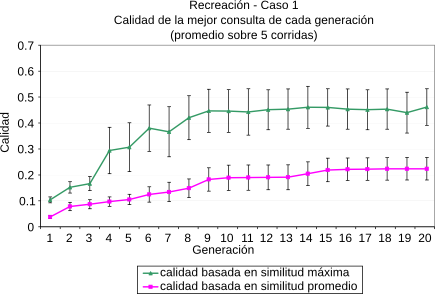
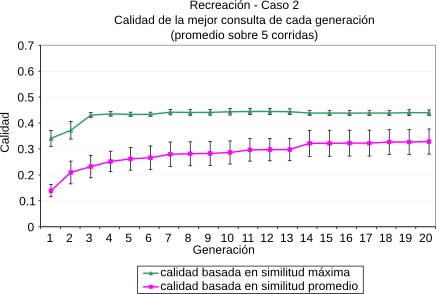
En [CLMB08] planteamos técnicas de optimización basadas en Algoritmos Genéticos [Gol89] para evolucionar ``buenos términos para consultas'' en el contexto de un tópico dado. Las técnicas propuestas hacen hincapié en la búsqueda de material novedoso que esté relacionado con el contexto de la búsqueda. Para evaluar el rendimiento de estos algoritmos, los mismos fueron implementados en su totalidad dentro de la plataforma propuesta y evaluados utilizando el motor de búsqueda web explicado en la Sección 5.3. Más detalles de los parámetros propios del algoritmo genético pueden encontrarse en [CLMB08]. Las métricas aplicadas fueron la similitud por coseno (Ecuación 2.1) y la similitud novedosa (Ecuación 5.1)(). En la Figura 5-7 se resumen los resultados obtenidos para los tópicos del ODP Negocios, Recreación y Sociedad. En cada uno de ellos se eligieron dos páginas al azar y se las utilizó como contexto inicial de búsqueda.
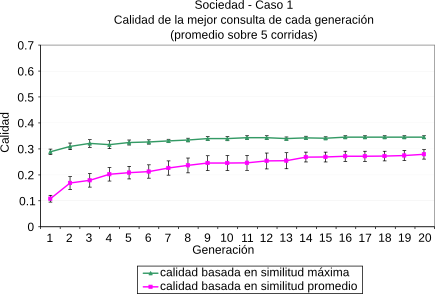
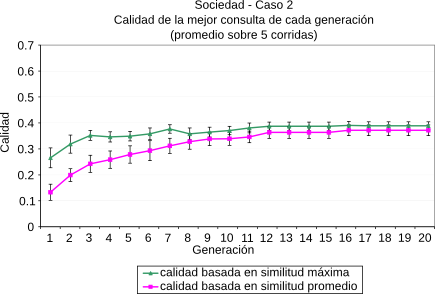
La formulación de consultas de alta calidad es un aspecto fundamental en la búsqueda basada en contexto. Sin embargo, el cálculo de la efectividad de una consulta es un desafío importante porque normalmente hay varios objetivos involucrados, como pueden ser la Precisión y la Cobertura. Los algoritmos genéticos presentados arriba son, en particular, algoritmos Mono-objetivo, lo que quiere decir que no son capaces de evaluar múltiples objetivos de forma simultánea. En [CLMB10] proponemos técnicas que pueden aplicarse para evolucionar consultas contextualizadas cuya calidad se basa en múltiples objetivos. Estos algoritmos fueron implementados utilizando la plataforma PISA [BLTZ03] y evaluados utilizando la plataforma de evaluación propuesta en esta tesis. La plataforma PISA está dedicada principalmente a la búsqueda multi-objetivo y divide el proceso de optimización en dos módulos. El primero contiene todo lo específico al problema que se está abordando, como son la evaluación de las soluciones y la representación del problema; este módulo fue el que se implementó dentro de la plataforma propuesta. El otro módulo contiene las partes que son independientes al problema, siendo la más importante el proceso de selección de los mejores individuos. En este módulo fueron utilizados los algoritmos de selección más utilizados en la literatura, y que ya están implementados dentro de PISA.
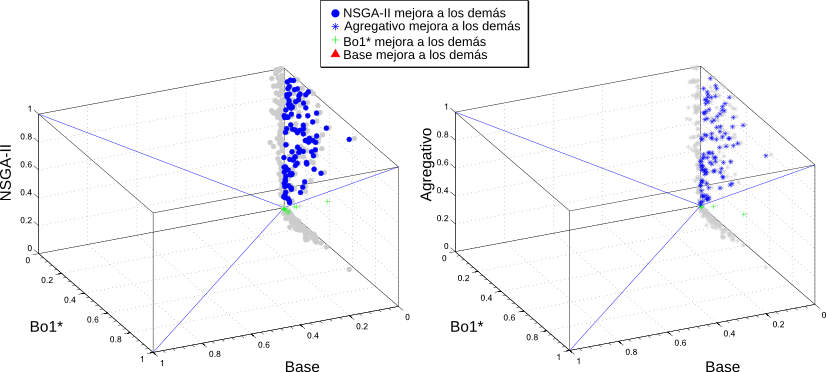
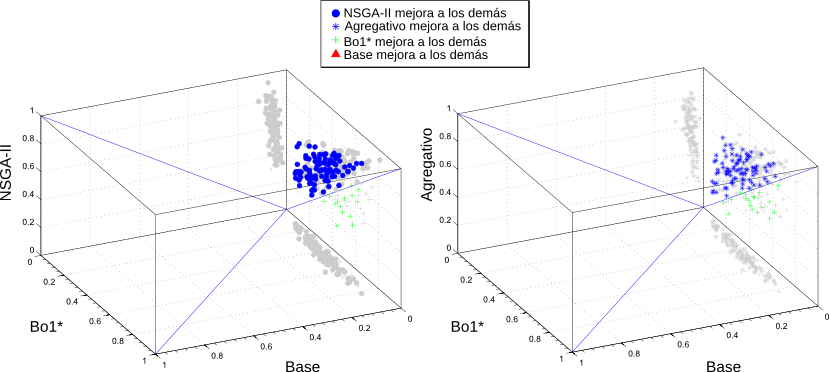
Las métricas que se utilizaron fueron la Precisión a un rango de 10 resultados ($P@10$) y la Cobertura. Además se definió una nueva métrica, $F^\star$, que es la media armónica de la $P@10$ y la Cobertura. En la comparación se estudió la efectividad de 3 algoritmos base contra 2 algoritmos propuestos. Estos últimos evolucionaron siguiendo dos objetivos simultáneos, la $P@10$ y la Cobertura. Uno de ellos fue el algoritmo NSGA-II [DAPM02] y el otro un algoritmo multi-objetivo agregativo que combina ambos objetivos utilizando $F^\star$. Dentro de los algoritmos que se utilizaron como base de la comparación tenemos un algoritmo Base que sólo genera consultas a partir del contexto inicial del usuario y no realiza ninguna evolución. El segundo es el ya mencionado algoritmo Bo1-DFR. Por último, dado que las comparaciones se realizaron utilizando el motor de búsqueda que cuenta con una colección local de documentos, se tenía información acerca de la relevancia de los resultados obtenidos por cada consulta. Es por esto que se implementó una versión supervisada del método Bo1-DFR, $Bo1^\star$, que a diferencia del algoritmo original, no crea las consultas con los mejores términos de los primeros resultados de la primera pasada (ver Subsección 2.2.2), sino que utiliza los mejores términos de los primeros documentos que se sabe que son relevantes (o sea, que pertenecen al tópico del contexto del usuario). En la Figura 5-8 se resumen los resultados obtenidos para las métricas Precisión y Cobertura de los algoritmos multi-objetivo. En este caso, para la creación del contexto inicial, se empleó una técnica similar a la mencionada en la Subsección 5.5.1, pero en esta oportunidad con 110 tópicos de la ontología elegidos al azar. Para más detalles de los parámetros de los algoritmos puede consultarse [CLMB10]. ResumenEn este capítulo se presentaron las evaluaciones realizadas a partir de la implementación del algoritmo incremental para la recuperación de información temática presentado en el capítulo anterior. Para esto se creó una plataforma general de evaluación de algoritmos de IR, presentándose su estructura y sus componentes principales. La misma soporta distintas fuentes de información, como pueden ser motores de búsqueda web o motores locales y es capaz de comunicarse con otras plataformas, como la plataforma Terrier y la plataforma PISA. Para crear la colección local de documentos se indexaron una gran cantidad de tópicos de la ontología DMOZ, seleccionados de forma de asegurar la calidad del conjunto de datos. Respecto de la métricas necesarias para las evaluaciones, se implementaron varias técnicas existentes y se propusieron otras, como la similitud novedosa que descarta a los términos presentes en las consultas, de modo de eliminar el sesgo introducido por ellos; y la precisión semántica, que tiene en cuenta relaciones de similitud parcial entre los tópicos de una ontología. La plataforma también mostró ser útil para la evaluación de otros algoritmos propuestos en el área de IR. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Última actualización el Lunes 25 de Junio de 2012 19:00 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

Caracterización Formal y Análisis Empírico de Mecanismos Incrementales de Bísqueda basados en Contexto por Carlos M. Lorenzetti se encuentra bajo una Licencia Creative Commons Atribución-NoComercial-CompartirDerivadasIgual 3.0 Unported.
Basada en una obra en bc.uns.edu.ar.