Caracterización Formal y Análisis Empírico de Mecanismos Incrementales de Búsqueda basados en ContextoTesis Doctoral en Ciencias de la Computación - Universidad Nacional del Sur por Carlos M. Lorenzetti Método incremental de recuperación de información basado en contextoLa calidad del material recuperado por los sistemas de búsqueda web basados en contexto es altamente dependiente del vocabulario que se usa para generar las consultas. Este trabajo propone aplicar un algoritmo semisupervisado para aprender incrementalmente nuevos términos. El objetivo es contrarrestar la diferencia de terminología entre las palabras que el usuario pueda utilizar para expresar una consulta y el vocabulario empleado en los documentos relevantes. La estrategia de aprendizaje utiliza una selección de documentos web recuperados incrementalmente, dependientes del tópico, para ajustar los pesos que se les asignan a los términos, de manera de reflejar su aptitud como descriptores y discriminadores del tópico del contexto del usuario. Este algoritmo novedoso aprende nuevos descriptores buscando términos que tienden a aparecer en documentos relevantes, y aprende buenos discriminadores identificando términos que tienden a ocurrir únicamente en el contexto de un tópico dado. El vocabulario enriquecido de esta forma permite la creación de consultas de búsqueda que son más efectivas que aquellas generadas directamente con los términos de la descripción inicial del tópico, y que son en general los que emplea un usuario promedio. Una evaluación sobre una gran colección de tópicos y utilizando métricas de rendimiento estándar y ad hoc sugiere que la técnica propuesta es superior a otras existentes en la literatura. IntroducciónLos primeros sistemas de IR fueron diseñados hace décadas para que los utilicen sólo algunos operadores entrenados. Este adiestramiento les permitía conocer de antemano: el lenguaje de consulta particular del sistema, el vocabulario particular del conjunto de documentos almacenados y la clase de documentos en la que estaban indexados. El acceso al sistema era a través de terminales de texto totalmente independientes y desconectadas de las computadoras que esos usuarios utilizaban para sus actividades laborales de todos los días. El contexto en el cual se utilizan los sistemas de IR ha cambiado enormemente desde esos días. La computadora personal invadió la vida cotidiana y, tan importante como este punto o más, la disponibilidad masiva del acceso a la Internet permite utilizar los sistemas de IR desde cualquier lugar y desde una gran cantidad de dispositivos. Esta nueva situación provocó también un cambio en la clase de usuarios que utilizan tales sistemas y las actitudes de dichos usuarios, así como también un cambio en la información con la que cuentan los sistemas a la hora de procesar un pedido. Los usuarios acceden a los repositorios de información desde la misma máquina sobre la cual escriben sus artículos, leen las noticias y navegan los sitios web que les interesan. Este nuevo escenario trae aparejado nuevos desafíos y nuevas oportunidades para los diseñadores de los sistemas de acceso a la información, para que creen sistemas más amigables al usuario, que a su vez saquen mayor provecho de este nuevo ámbito colmado de información. El problema del contexto en los sistemas de IREl aumento de la disponibilidad y del uso de los sistemas no ha traído aparejado un crecimiento en la cantidad de información que el usuario le comunica al sistema, ni tampoco ha habido demasiados cambios en el diseño de los sistemas de interacción humano computadora. Los usuarios continúan manifestando sus pedidos a través de términos dentro de una consulta que luego se envía a un sistema que está aislado del contexto que produjo ese pedido. Si miramos el problema desde el punto de vista de la interfaz de usuario, el lenguaje natural parece ser el medio ideal para la comunicación entre el sistema y el usuario. Desafortunadamente el sistema está separado de toda la información crítica que se necesita para su comprensión, incluso si el mismo intenta entender y representar los conceptos que están contenidos en los documentos indexados o en las consultas que procesa. En otras palabras, esto quiere decir que los sistemas de información están aislados del contexto en el cual se producen los pedidos. Cuando las personas recurren a un sistema de IR, en general, es porque quieren resolver algún problema, o lograr algún objetivo, para el cual su estado de conocimiento es insuficiente. Esto sugiere que no saben qué sería útil para esto y, por lo tanto, usualmente no son capaces de especificar de forma precisa las características más importantes de los objetos que son potencialmente útiles. Sin embargo, las consultas que se ingresan suelen basarse en un contexto que puede ayudar a interpretarlas y procesarlas. Por ejemplo, si el usuario está editando o leyendo un documento sobre un tópico específico, quizás quiera explorar material nuevo relacionado con ese tópico. Si no se tiene acceso a este contexto las consultas se vuelven ambiguas, con los consecuentes resultados incoherentes y usuarios descontentos. Veamos el siguiente ejemplo que clarifica esta situación. Consideremos un pedido de ``información acerca de java'', uno de los ejemplos más comunes en la literatura, y observemos cómo cambia drásticamente la utilidad de los resultados si manipulamos el contexto de la búsqueda en los siguiente escenarios.
Estos escenarios muestran tres clases de problemas asociados con la interpretación de una consulta sin la consideración de un contexto [BHB01].
Los ejemplos mencionados nos ayudan a ver algunos de los grandes problemas con los que se encuentran los sistemas actuales de IR al intentar responder a consultas sin tener en cuenta el contexto en el cual éstas se producen. Además, para empeorar la situación, se ha mostrado que las consultas enviadas a los motores de búsqueda tienen un promedio de 2.21 palabras [JSBS98] y, en una consulta de dos términos, es muy fácil ver que no existe la información suficiente para discernir los objetivos del usuario, o incluso para inferir el sentido correcto de las palabras. Por lo tanto, vemos que la Búsqueda Basada en Contexto es el proceso de buscar información relacionada con el contexto temático del usuario [BHB01,MLR05,KCMK06,RB06]. Las búsquedas automáticas basadas en contexto sólo tienen éxito si las consultas reflejan la semántica que tienen los términos en el contexto bajo análisis. Desde un punto de vista pragmático, los términos toman significado de acuerdo a la forma en la que se los utilice y de acuerdo con su co-ocurrencia con otros términos. Luego, explotar grandes conjuntos de datos (como la Web) guiados por el contexto del usuario puede ayudar a descubrir el significado de un pedido de información por parte del usuario y a identificar buenos términos para refinar consultas incrementalmente. Intentar encontrar buenos subconjuntos de términos para crear las consultas apropiadas es un problema combinatorial, y la situación empeora cuando atacamos un espacio de búsqueda abierto, como por ejemplo, cuando las consultas pueden incorporar términos que no pertenecen al contexto actual. Esta no es una situación inusual cuando intentamos refinar consultas basadas en una descripción de un contexto que contiene pocos términos y, a su vez, poseemos un corpus externo de gran tamaño. Sin embargo, éste no es un problema nuevo en el área. La siguiente sección analiza algunos trabajos previos. AntecedentesPara acceder a información relevante es necesario generar las consultas apropiadas. En la búsqueda web basada en texto, los pedidos de información de los usuarios y los posibles recursos de información se caracterizan con términos. Para medir la importancia relativa de estos términos, en los métodos tradicionales de IR, se utilizan pesos (ver Sección 2.1). Sin embargo, como lo han mostrado varias investigaciones, surgen problemas a la hora de intentar aplicar los esquemas convencionales de IR para medir la importancia de los términos en sistemas de búsqueda de datos en la Web [KT00,Bel00]. Una dificultad que aparece es que estos métodos no tienen acceso a una colección predefinida de documentos, generando dudas acerca de la aplicabilidad de tales esquemas en la medición de la calidad de los términos en las búsquedas web. Además, esta calidad dependerá de la tarea que se esté realizando; la noción de importancia tiene distintas interpretaciones dependiendo de si el término se necesita para la construcción de una consulta, para la generación de índices, para resumir un documento o para determinar similitud (Sección 2.3). Por ejemplo, un término que es útil como descriptor del contenido de un documento y, por lo tanto útil para juzgar similitud, puede fallar si se lo utiliza como discriminante y ser ineficaz como término en una consulta, ya que lograría muy baja precisión en los resultados. Pero, podría darse el caso que se mejoren los resultados de esa búsqueda si se combina con otros términos que discriminen entre resultados buenos y malos. En particular, la mayoría de los métodos que emplean realimentación de relevancia (Subsección 2.2.2)() eligen los términos más frecuentes de los documentos que se recuperaron en la primera pasada, con la esperanza de que éstos ayuden al proceso de recuperación. Este criterio de selección algunas veces brinda términos útiles, pero otras veces términos inútiles o incluso, términos que deterioran la calidad de los resultados. En [CNGR08] se propone agregar términos en función de su impacto en la efectividad de los documentos recuperados, mostrando que tratar de separar los buenos términos de los malos basándose en su frecuencia es una tarea muy difícil. Proponen como alternativa el uso de un clasificador que se alimenta con un conjunto novedoso de propiedades, tales como la coocurrencia y la proximidad con los términos de la consulta inicial. La comunidad de IR ha investigado desde hace décadas los roles de los términos como descriptores y discriminadores. Desde el trabajo de Spärck Jones sobre la interpretación estadística de la especificidad de un término [SJ72], el poder discriminante de un término ha sido explicado estadísticamente, como una función del uso de dicho término. De la misma manera, la importancia de los términos como descriptores de un contenido ha sido tradicionalmente estimada midiendo su frecuencia dentro de un documento. La combinación de descriptores y discriminadores da lugar a esquemas para la medición de la relevancia de los términos como el conocido modelo de evaluación TF-IDF (Subsección 2.1.2). Por otro lado, se ha avanzado mucho en el problema del cálculo del grado de información que tiene un término a lo largo de un corpus [AvR02,RJ05,CvR09]. Una vez que ese grado se calcula sobre un conjunto de términos, se pueden formular mejores consultas. El principal problema de los métodos de refinamiento de consultas es que su efectividad, como se dijo, está correlacionada con la calidad de los documentos mejor clasificados recuperados en la primera pasada. Por otro lado, si se cuenta con un contexto temático, el proceso de refinamiento de consultas puede guiarse calculando una estimación de la calidad de los documentos recuperados. Esta estimación puede utilizarse para predecir cuáles términos pueden ayudar a refinar las consultas subsiguientes. Durante los últimos años se han propuesto muchas técnicas para generar consultas desde el contexto del usuario [BHB01,KCMK06]. Otros métodos realizan el proceso de expansión y refinamiento de consultas con la explícita intervención del usuario [SW02,BSWZ03]. Sin embargo poco se ha hecho en el campo de los métodos semisupervisados que saquen ventaja simultáneamente del contexto del usuario y de los resultados que obtienen del proceso de búsqueda. Trabajo relacionadoLos sistemas existentes en la literatura pueden clasificarse en cuatro categorías: realimentación de relevancia, sistemas que hacen uso de perfiles de usuario, métodos basados en técnicas implícitas y explícitas de desambiguación de términos y métodos de modelado simbólico de usuarios.
A continuación se mencionarán algunos sistemas, desarrollados en la literatura, que asisten al usuario en la tarea de recuperación de información. Asistentes para el Manejo de ContenidoEn [BH99b] se desarrollaron una clase de sistemas llamados Asistentes para el Manejo de Contenido (IMA). Los IMAs descubren material relacionado en representación del usuario, actuando como un intermediario inteligente entre él y los sistemas de recuperación de información. Un IMA observa la interacción del usuario con las aplicaciones diarias (p. ej. un editor de texto o un navegador web), y usa estas observaciones para anticipar sus necesidades de información. Entonces intenta satisfacer estas necesidades accediendo a los sistemas de IR tradicionales (p. ej. motores de búsqueda en Internet, resúmenes de artículos, entre otros), filtrando los resultados y presentándolos al usuario. Además, la arquitectura de los IMAs proporciona una plataforma potente para contextualizar las consultas ingresadas explícitamente por un usuario conectándolas con las tareas que está realizando. WatsonWatson utiliza información contextual extraída de los documentos que los usuarios están manipulando para generar consultas web [BHB01]. Para la selección de los mejores términos para conformar las consultas utiliza diversas técnicas de extracción y evaluación de términos. Luego filtra los resultados, agrupa las páginas similares y las presenta como sugerencias al usuario. Remembrance AgentEl Agente de la Memoria (RA) es un programa que ``aumenta la memoria humana'' mostrando una lista de documentos que pudieran ser relevantes para el contexto actual del usuario [RS96]. A diferencia de muchos otros sistemas de esa época, el RA se ejecutaba sin la intervención del usuario. Esta interfase no invasiva permitía al usuario tomar las sugerencias que le parecían interesantes o directamente ignorarlas. Su filosofía de diseño se basa en que, como un programa que se está ejecutando y actualizando continuamente, nunca debe distraer al usuario de su tarea principal, sólo debe mejorarla. Sugiere fuentes de información que pueden llegar a ser relevantes para la tarea actual del usuario en la forma de resúmenes de una línea al final de la pantalla. En ese lugar la información puede ser fácilmente monitoreada, pero no distrae del trabajo que se está realizando. En caso de aceptar la sugerencia, el usuario puede visualizar el texto completo presionando una tecla. LetiziaLetizia es un agente intermediario que asiste al usuario que está navegando la Web [Lie95]. A medida que el usuario trabaja en la forma habitual con un explorador web, el agente registra el comportamiento del usuario y trata de traer por adelantado ítems de interés explorando de forma concurrente y autónoma los enlaces de la página que el usuario está viendo en ese momento. Automatiza una estrategia de navegación que consiste en una búsqueda mejorada, con la técnica del primero-mejor, infiriendo los intereses del usuario a partir de su comportamiento. Utiliza con conjunto de heurísticas simples para modelar cuál podría ser el comportamiento de navegación del usuario. A pedido, puede visualizar una página conteniendo sus recomendaciones actuales, en la cual se puede elegir seguir una recomendación o regresar a las actividades convencionales de navegación. WebWatcherWebWatcher es un agente que ayuda interactivamente a los usuarios a localizar la información que desean, utilizando conocimiento aprendido acerca de cuáles son los hipervínculos que mejor pueden guiar al usuario a la información que está buscando [AFJM95]. WebWatcher es un agente de búsqueda de información que se ``invoca'' ingresando en su página web e indicando en un formulario qué información se necesita (p. ej., una publicación de algún autor). Entonces el agente lleva al usuario a una página nueva que contiene una copia de la página recomendada más algunos agregados que asisten al usuario a medida que sigue los hipervínculos hacia la información buscada. Mientras el usuario navega la Web, WebWatcher va aprendiendo y usa ese conocimiento para recomendar hipervínculos prometedores, resaltándolos en las páginas. SenseMakerSenseMaker es una interfase de exploración de fuentes de información (principalmente referencias a artículos) heterogéneas, como p. ej. motores de búsqueda web y de bibliografía de distintos proveedores [BW97]. El sistema puede ``unir'' (en forma de clusters) datos que muestran cierto grado de similitud, de acuerdo a algún criterio definido por el usuario. Por ejemplo, para páginas web, un criterio puede ser agrupar aquellos sitios que se refieran a la misma página, o en el caso de artículos, por título o autor. El sistema permite que el usuario elija alguno de varios criterios para visualizar los resultados recuperados, así como también para eliminar elementos duplicados. Permite a los usuarios experimentar de forma iterativa con distintas vistas de los resultados. Dentro de una vista se puede reducir la complejidad de la visualización filtrando los campos mostrados y agrupando resultados similares. También es posible evolucionar consultas por medio de la expansión o la sustitución de términos. FabFab es un sistema recomendador colaborativo híbrido basado en contenido, que aprende a navegar por la Web en representación de un usuario [BS97]. Genera recomendaciones utilizando un conjunto de agentes de recolección (que buscan las páginas de un determinado tema) y agentes de selección (que buscan páginas para un usuario en particular). Las valuaciones explícitas de los usuarios de las páginas que el sistema le recomendó se combinan con algunas heurísticas para: actualizar los perfiles de los agentes personales, eliminar agentes que no tuvieron éxito, y duplicar a los exitosos. Es un sistema híbrido porque propone eliminar las debilidades y aprovechar las ventajas de los recomendadores colaborativos y de los basados en contenidos al combinarlos en uno solo. Los sistemas de recomendación basados en contenido intentan recomendar objetos similares a aquellos a los cuales el usuario a seleccionado en el pasado, mientras que los sistemas recomendadores colaborativos identifican otros usuarios cuyos gustos sean similares a un usuario dado y le recomienda objetos que otros seleccionaron. BroadwayEl sistema Broadway es un sistema de razonamiento basado en casos (CBR), que monitorea la actividad de navegación del usuario y da consejos reutilizando casos que se extraen del historial de navegación de otros usuarios [JT97]. Los consejos se basan en una lista ordenada en base a la similitud con los documentos visitados. El paradigma CBR se utiliza para aprender el conjunto de casos relevantes de los historiales de navegación de los usuarios, los cuales son utilizados para mejorar y mantener actualizado el proceso de asesoramiento. El sistema se basa en la siguiente hipótesis: si dos usuarios han recorrido la misma secuencia de páginas, pueden tener objetivos similares y, por lo tanto, un usuario puede aprovechar los documentos que el otro usuario consideró relevantes. SiteSeerSiteseer es un sistema de recomendación de páginas web que utiliza la estructura de los Favoritos de un navegador web, para predecir y recomendar páginas relevantes [RP97]. El sistema interpreta que las páginas contenidas en los Favoritos son una declaración implícita de interés en su contenido y que las carpetas en las que se agrupan esas páginas son una indicación de la coherencia semántica entre los elementos. Además trata a las carpetas como un sistema de clasificación personal, lo cual posibilita contextualizar las recomendaciones en clases definidas por el usuario. Siteseer aprende con el tiempo las preferencias y categorías de cada usuario, y a su vez aprende de cada página web a qué comunidades pertenecen sus usuarios. Luego ofrece recomendaciones personalizadas organizadas dentro de las carpetas propias de cada usuario. Siteseer emplea los descubrimientos de un usuario como recomendaciones implícitas para otros, basándose en los Favoritos que pueden encontrarse en un conjunto de revisores confiables. Un usuario es confiable si el grado de solapamiento de sus carpetas es suficientemente alto. La similitud se calcula a través del contenido de las carpetas, sin derivar ningún valor semántico del contenido de las páginas ni del título de las carpetas. De esta manera crea dinámicamente comunidades virtuales de intereses, particulares a cada usuario y específicas para cada categoría de interés de éste. Al calcular la pertenencia de forma relativa a cada carpeta, el sistema no impone rigidez a las categorías y logra ser útil a usuarios con intereses relativamente poco frecuentes o muy específicos. Syskill & WebertSyskill & Webert es un agente que aprende a evaluar páginas en la Web y decide qué páginas pueden interesarle a un usuario [PMB96]. Los usuarios califican las páginas que visitan en una escala de tres puntos y el agente aprende el perfil del usuario analizando la información que extrae de cada página. Este perfil se utiliza para sugerirle al usuario enlaces que podrían interesarle, y para construir consultas que se envían a un motor de búsqueda para descubrir nuevas páginas de interés. El sistema aprende un perfil separado para cada tópico de interés del usuario. Esto ayuda a la precisión del aprendizaje de cada tópico. Cada uno de estos posee una página web con los URLs que se indexaron del tópico. De esta manera el sistema permite a un usuario usar esta página como un punto de partida para la exploración. La utilización del sistema de esta forma tiene la limitación de que debe existir una página con un buen conjunto de URLs sobre un tópico. Si esto no ocurriera, el agente envía consultas, basadas en el perfil del usuario, a un motor de búsqueda para recolectar páginas nuevas. ExtenderEl sistema Extender aplica técnicas de búsqueda incremental para construir descripciones más completas del contexto del usuario y las utiliza para la identificación de tópicos relacionados con ese contexto [MLR05]. El objetivo del sistema es ayudar a expertos en la construcción de modelos de conocimiento, dándole sugerencias sobre nuevos tópicos. Estas sugerencias son pequeños conjuntos de términos que tratan de conducirlo al significado del tópico (p. ej., una etiqueta de la forma ``lunar, luna, explorador'' se utiliza para describir el tópico Misión de exploración a la Luna). El sistema comienza a partir de un mapa conceptual [Aus63] e iterativamente hace búsquedas en la Web para encontrar material novedoso relacionado con todo el mapa. También permite que el usuario resalte algún tema para forzar la búsqueda hacia ese concepto. En cada iteración, los documentos recuperados se representan como una matriz de documentos-términos, se hace clustering para identificar los tópicos dentro del conjunto y el material que se considera irrelevante se descarta. Este proceso continúa hasta alcanzar algún criterio de convergencia del tópico o un límite en la cantidad de iteraciones. SuitorSuitor es una colección de ``agentes atentos'' que recolectan información de los usuarios monitoreando su comportamiento y su contexto desde múltiples canales, incluyendo la mirada, las teclas presionadas en el teclado, el movimiento del mouse, los sitios visitados y las aplicaciones que se están ejecutando [MBCS00]. Esta información se utiliza para recuperar de la Web y otras bases de datos, material relevante al contexto del usuario. Suitor observa al usuario, lo modela y se anticipa a sus necesidades. Esta clase de sistemas incluye a los mayordomos, los dispositivos comerciales como el TiVo, que graba automáticamente programas de televisión que le gustan al usuario, y sitios como Amazon.com que monitorean las costumbres de compra y el comportamiento de navegación y le sugieren al usuario nuevos libros que podrían interesarle. En la siguiente sección se presentará una propuesta para refinar consultas temáticas, basada en el análisis de los términos que se encuentran en el contexto del usuario y en los resultados recuperados incrementalmente. Una Plataforma novedosa para la selección de términosEste trabajo presenta técnicas generales para aprender incrementalmente términos relevantes asociados a un contexto temático. Específicamente se estudian tres preguntas:
La contribución de este trabajo es un algoritmo semisupervisado que aprende incrementalmente nuevo vocabulario con el propósito de mejorar consultas. El objetivo es que las consultas reflejen la información contextual y así puedan recuperar efectivamente material relacionado semánticamente. En este trabajo se utilizó una métrica estándar de evaluación del rendimiento y dos métricas ad hoc para descubrir si estas consultas son mejores que las generadas utilizando otros métodos. Estas nuevas métricas se presentarán en detalle en la sub:metricas_propuestas. La pregunta principal que guió este trabajo es cómo aprender términos específicos a un contexto basándonos en la tarea del usuario y en una colección abierta de documentos web recuperados incrementalmente. De ahora en más, asumiremos que la tarea del usuario está representada como un conjunto de términos cohesivos que resumen el tópico del contexto del usuario. Consideremos un ejemplo que involucra la Máquina Virtual de Java, descripto por los siguientes términos:
Los términos específicos a un contexto juegan distintos roles. Por ejemplo, el término java es un buen descriptor del tópico para el común de las personas. Por otro lado, términos como jvm y jdk (acrónimos de ``Java Virtual Machine'' y ``Java Development Kit'' respectivamente) pueden no ser buenos descriptores del tópico para esas mismas personas, pero son efectivos recuperando información similar al tópico cuando se los utiliza en una consulta. Luego, jvm y jdk son buenos discriminadores del tópico. En [MLRM04] se propone estudiar el poder descriptivo y discriminante de un término basándose en su distribución a través de los tópicos de las páginas recuperadas por un motor de búsqueda. Allí, el espacio de búsqueda es la Web completa y el análisis del poder descriptivo o discriminante de un término está limitado a una pequeña colección de documentos que se va construyendo incrementalmente y que varía en el tiempo. A diferencia de los esquemas de IR tradicionales, los cuales analizan una colección predefinida de documentos y buscan en ella, los métodos propuestos utilizan una cantidad limitada de información para medir la importancia de los términos y documentos así como también para la toma de decisiones acerca de cuáles términos conservar para análisis futuros, cuáles descartar, y qué consultas adicionales generar. Para distinguir entre descriptores y discriminadores de tópicos se argumenta que buenos descriptores de tópicos pueden encontrarse buscando aquellos términos que aparecen en la mayoría de los documentos relacionados con el tópico deseado. Por otro lado, buenos discriminadores de tópicos pueden hallarse buscando términos que sólo aparecen en documentos relacionados con el tópico deseado. Ambos tipos de términos son importantes a la hora de generar consultas. Utilizar términos descriptores del tópico mejora el problema de los resultados falso-negativos porque aparecen frecuentemente en páginas relevantes. De la misma manera, los buenos discriminadores de tópicos ayudan a reducir el problema de los falsos-positivos, ya que aparecen principalmente en páginas relevantes. Cálculo del Poder Descriptivo y del Poder DiscriminanteComo una primera aproximación al cálculo del poder descriptivo y discriminante se comienza con un conjunto de $m$ documentos y $n$ términos. En primera medida se construye una matriz de $m\times n$ elementos, de forma tal que ${\bf H}[i,j]=p$, donde $p$ es el número de apariciones del término $k_i$ en el documento $d_j$. En particular se puede asumir que uno de los documentos (p. ej., $d_0$) corresponde al contexto inicial. El ejemplo siguiente muestra esta situación:
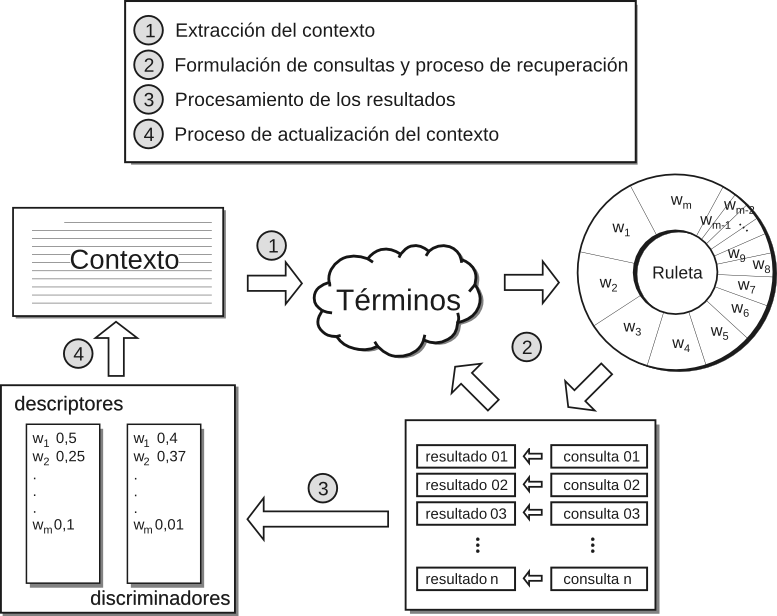
La matriz $\bf H$ permite formalizar las nociones de buenos descriptores y buenos discriminadores. Definición 12 [MLRM04] Se define el poder descriptivo de un término en un documento como la función $\lambda:\{d_0,\ldots,d_{m-1}\}\times \{k_0,\ldots,k_{n-1}\} \rightarrow [0,1]$: $$ \begin{align*} \lambda(d_j,k_i) = \frac{\mathbf{H}[i,j]} {\sqrt{\sum_{h=0}^{n-1} (\mathbf{H}[h,j])^2}}. \end{align*}$$ Definición 13 [MLRM04] Se define una función ${\mathrm s}(p)$ tal que ${\mathrm s}(p)=1$ cuando $p>0$ y ${\mathrm s}(p)=0$ en cualquier otro caso. Luego se define el poder discriminante de un término en un documento como la función $\delta: \{d_0,\ldots,d_{m-1}\}\times \{k_0,\ldots,k_{n-1}\} \rightarrow [0,1]$: $$\begin{align*} \delta(d_j, k_i) = \frac{{\mathrm s}(\mathbf{H}[i,j])} {\sqrt{\sum_{h=0}^{m-1} {\mathrm s}(\mathbf{H}[i,h])}}. \end{align*}$$ Se puede ver que $\lambda$ y $\delta$ satisfacen las siguientes condiciones: $$\begin{align*} \sum_{h}{(\lambda(d_j,k_h))^2}=1\mbox{ y }\sum_{h}{(\delta(d_h,k_i))^2}=1. \end{align*}$$Dado el término $k_i$ en el documento $d_j$, el término tendrá un poder descriptivo alto en $d_j$ si aparece frecuentemente en él, mientras que tendrá un alto poder discriminante si tiende a aparecer sólo en él (o sea, aparece esporádicamente en otros documentos). Para los términos del ejemplo, el poder descriptivo y el poder discriminante serían los siguientes: $$\begin{array}{*{20}c} {} & {\begin{array}{*{20}c} \lambda(d_0,k_i) \\ \end{array}} & {\begin{array}{*{20}c} \delta(d_0,k_i) \\ \end{array}} \\ {\begin{array}{*{20}c} {\tt java} \\ {\tt machine} \\ {\tt virtual} \\ {\tt language} \\ {\tt programming} \\ {\tt coffee} \\ {\tt island} \\ {\tt province} \\ {\tt jvm} \\ {\tt jdk} \\ \end{array}} & {\left( {\begin{array}{*{20}c} 0.718 \\ 0.359 \\ 0.180 \\ 0.180 \\ 0.539 \\ 0.000 \\ 0.000 \\ 0.000 \\ 0.000 \\ 0.000 \\ \end{array}} \right)} & {\left( {\begin{array}{*{20}c} 0.447 \cr 0.500 \cr 0.577 \cr 0.500 \cr 0.577 \cr 0.000 \cr 0.000 \cr 0.000 \cr 0.000 \cr 0.000\cr \end{array}} \right)} \\ \end{array}$$Los pesos anteriores reflejan algunas de las limitaciones de esta primera aproximación. Por ejemplo, los pesos asociados con los términos jvm y jdk no reflejan su importancia como discriminadores del tópico analizado. De la misma manera que las populares medidas TF e IDF (explicadas en la Subsección 2.1.2), las funciones $\lambda$ y $\delta$ permiten descubrir términos que son buenos descriptores y buenos discriminadores de un documento, en lugar de buenos descriptores y discriminadores del tópico del documento. El objetivo es desarrollar nociones de descriptores y discriminadores de tópicos que sean aplicables a la Web. En lugar de extraer descriptores y discriminadores directamente del contexto del usuario, se busca extraerlos del tópico de ese contexto. Para realizar esta tarea es necesario un método incremental que caracterice el tópico del contexto del usuario, lo cual se lleva a cabo identificando los documentos que son similares a ese contexto. Asumiendo que el contexto y los documentos recuperados de la Web están representados como vectores en un espacio de términos, para determinar qué tan similares son dos documentos $d_j$ y $d_k$ se adopta la medida de similitud por coseno (Definición 3, Ecuación 2.1), que en términos de $\lambda$ queda expresada como: $$ \mathit{sim}(d_j,d_k) = \sum_{h=0}^{n-1}[\lambda(d_j,k_h)\cdot\lambda(d_k,k_h)]. $$Los valores de similitud entre el contexto del usuario ($d_0$) y los otros documentos del ejemplo son los siguientes: $$\begin{array}{*{20}c} {} & {\begin{array}{*{20}c} d_1 \\ \end{array}} & {\begin{array}{*{20}c} d_2 \\ \end{array}} & {\begin{array}{*{20}c} d_3 \\ \end{array}} & {\begin{array}{*{20}c} d_4 \\ \end{array}} \\ {\begin{array}{*{20}c} {\mathit{sim}(d_0,d_j) = } \\ \end{array}} & {\left( {\begin{array}{*{20}c} 0,399 \\ \end{array}} \right.} & { {\begin{array}{*{20}c} 0,840 \\ \end{array}}}& {{\begin{array}{*{20}c} 0,857 \\ \end{array}} } & {\left. {\begin{array}{*{20}c} 0.371 \cr \end{array}} \right)} \\ \end{array}$$La noción de descriptor de tópico se definió informalmente con anterioridad como ``los términos que ocurren frecuentemente en el contexto de un tópico''. Definición 14 [MLRM04] Se define el poder descriptivo de un término en el tópico de un documento como la función $\Lambda : \{d_0,\ldots, d_{m-1}\} \times \{k_0, \ldots, k_{n-1}\} \to [0,1]$. Como se definió informalmente antes, un término es un buen discriminador de un tópico si ``tiende a aparecer sólo en documentos asociados con ese tópico''. Definición 15 [MLRM04] Se define el poder discriminante de un término en el tópico de un documento como la función $\\Delta:\{d_0,\ldots,d_{m-1}\}\times\{k_0,\ldots,k_{n-1}\} \rightarrow [0,1]$ que se calcula: $$ \begin{align*} \begin{array} {rl} \\Delta(d_j,k_i) = & \sum\nolimits_{% \begin{subarray}{l}% h=0 \\ % h\neq j% \end{subarray}% }^{m-1}{[\mathit{sim}(d_j,d_h) \cdot [\delta(d_h,k_i)]^2]}. \end{array} \end{align*} $$ Así el poder discriminante de un término $k_i$ en el tópico del documento $d_j$ es el promedio ponderado de la similitud entre $d_j$ y otros documentos discriminados por $k_i$. Los siguientes valores son el poder descriptivo y discriminante de los términos del ejemplo: $$\begin{array}{*{20}c} {} & {\begin{array}{*{20}c} \Lambda(d_0,k_i) \\ \end{array}} & {\begin{array}{*{20}c} \Delta(d_0,k_i) \\ \end{array}} \\ {\begin{array}{*{20}c} {\tt java} \\ {\tt machine} \\ {\tt virtual} \\ {\tt language} \\ {\tt programming} \\ {\tt coffee} \\ {\tt island} \\ {\tt province} \\ {\tt jvm} \\ {\tt jdk} \\ \end{array}} & {\left( {\begin{array}{*{20}c} 0.385 \cr 0.158 \cr 0.014 \cr 0.040 \cr 0.055 \cr 0.089 \cr 0.064 \cr 0.040 \cr 0.032 \cr 0.124 \\ \end{array}} \right)} & {\left( {\begin{array}{*{20}c} 0.493 \cr 0.524 \cr 0.566 \cr 0.517 \cr 0.566 \cr 0.385 \cr 0.385 \cr 0.385 \cr 0.848 \cr 0.848 \cr \end{array}} \right)} \\ \end{array} $$Con las nociones de descriptores y discriminadores de tópicos es posible aprender términos nuevos y específicos a un contexto y reajustar los pesos de los existentes. Esto produce una mejor representación del contexto de búsqueda del usuario, mejorando el proceso de refinamiento de consultas y el filtrado basado en ese contexto. Podemos apreciar en el ejemplo, que los términos jvm y jdk, que no pertenecían al contexto inicial del usuario, resultaron ser excelentes discriminadores del tópico. Mecanismo incremental para refinar consultas temáticasEn esta sección se abordarán los detalles del mecanismo incremental para el refinado de consultas temáticas propuesto. Ésta es una de las contribuciones de esta tesis. La propuesta es aproximar el poder descriptivo y discriminativo de los términos del contexto bajo análisis con el propósito de generar buenas consultas. Esta aproximación adapta el mecanismo típico de realimentación de relevancia para que considere un contexto temático en evolución $\mathcal {C}_i$. Un esquema del método incremental para el refinamiento de consultas basado en un contexto temático se muestra en la Figura 4.1 y se resume en el Algoritmo 1. Algoritmo 1 Principal
$i \Leftarrow 0$
$i \Leftarrow i + 1$ hasta $(i > v) \wedge FinalConvergence$ Algoritmo 2 Calcular $\mathcal{C}_i$
$j \Leftarrow 0$
$j \Leftarrow j+1$ hasta $(j > u) \wedge PhaseConvergence$ Algoritmo 3 Prueba-de-convergencia Requerir: $\mu > \nu$
$PhaseConvergence \Leftarrow max(\mathit{sim}(Results, \mathcal{C}_i)) < \mu$
El sistema lleva a cabo una serie de fases con el objetivo de aprender mejores descripciones de un contexto temático. En la figura esto está representado por el ciclo de pasos que van desde el paso 1 al paso 4. Al final de cada fase se actualiza la descripción del contexto con el nuevo material aprendido (paso 4). En una fase $\mathcal{P}_i$ dada, se representa el contexto con un conjunto de términos con sus respectivos pesos. La estimación de la importancia del término $k$ en el contexto $\mathcal{C}$ durante la fase $i$ se representa con $w^{\mathcal{P}_i}(k,\mathcal{C})$. Si $k$ aparece en el contexto inicial, entonces el valor de $w^{{\mathcal{P}_0}}(k,\mathcal{C})$ se inicializa con la frecuencia normalizada del término $k$ en $\mathcal{C}$, mientras que los términos que no son parte del contexto $\mathcal{C}$ se asumen en 0. Cada fase a su vez evoluciona a través de lo que se denominó una serie pruebas (paso 2); en ellas se formulan una serie de consultas, se analizan los resultados obtenidos y se calcula el poder descriptivo y discriminante de los nuevos términos descubiertos. La generación de las consultas en cada una de las pruebas se implementó a través de un mecanismo de selección por ruleta, en donde la probabilidad de elegir un término en particular $k$, para que forme parte de una consulta, es proporcional a $w^{\mathcal{P}_i}(k,\mathcal{C})$. La técnica de selección por ruleta se utiliza comúnmente en los Algoritmos Genéticos [Hol75] para la elección de las soluciones potencialmente útiles que luego se recombinarán; la probabilidad de selección está dada por el nivel de aptitud del individuo. Este método produce una exploración no determinística del espacio de términos que favorece a los términos más aptos. La estimación del poder descriptivo y discriminate de un término $k$ para un contexto $\mathcal{C}$ en una fase $i$ en una prueba $j$ se calcula incrementalmente de la siguiente manera: $$ \begin{align*} w^{(i,j+1)}_\Lambda(k,\mathcal{C}) &= \alpha . w^{(i,j)}_\Lambda(k,\mathcal{C}) + \beta . \Lambda^{(i,j)}(k,\mathcal{C})\text{,}\\ w^{(i,j+1)}_\Delta(k,\mathcal{C}) &= \alpha . w^{(i,j)}_\Delta(k,\mathcal{C}) + \beta . \Delta^{(i,j)}(k,\mathcal{C})\text{.} \end{align*} $$ Se asume que los valores iniciales de cada prueba son nulos, $w^{(i,0)}_\Lambda(k,\mathcal{C})=w^{(i,0)}_\Delta(k,\mathcal{C})=0$ y se utilizan los resultados recuperados durante cada prueba $j$ para calcular el poder descriptivo, $\Lambda^{(i,j)}(k,\mathcal{C})$, y discriminante, $\Delta^{(i,j)}(k,\mathcal{C})$, del término $k$ para el tópico $\mathcal{C}$ respectivamente. Las constantes $\alpha$ y $\beta$ determinan la cantidad de información que el sistema recordará de una prueba a la siguiente. Cuanto mayor sea el valor asignado a la constante $\alpha$ más tiempo perdurará el conocimiento aprendido y menos influencia tendrán los nuevos documentos recuperados en el cálculo del poder descriptivo y discriminante de un término. Monitoreo de la efectividadCon el objetivo de medir la efectividad que el sistema alcanza en cada iteración, se calculan un conjunto de métricas sobre el material recuperado. Las medidas que pueden aplicarse para guiar al algoritmo son las clásicas del área de IR (como las vistas en la Sección 3.4) u otras nuevas, que serán definidas en el capítulo siguiente. Si luego de una ventana de $u$ intentos la efectividad no supera un determinado nivel $\mu$ (o sea, que no se han observado mejoras importantes luego de cierto número de intentos), el sistema provoca un cambio de fase para explorar nuevas regiones del vocabulario que sean potencialmente útiles. Un cambio de fase puede verse como un salto en el vocabulario, lo cual puede pensarse como una transformación importante de la representación del contexto (típicamente una mejora). Si se realiza un cambio de fase durante la prueba $j$, el valor de $w^{{\mathcal{P}_i}}_\Lambda(k,\mathcal{C})$ queda determinado como $w^{(i,j)}_\Lambda(k,\mathcal{C})$ y $w^{{\mathcal{P}_i}}_\Delta(k,\mathcal{C})$ como $w^{(i,j)}_\Delta(k,\mathcal{C})$. $$ \begin{align*} w^{{\mathcal{P}_{i+1}}}(k,\mathcal{C}) = \gamma . w^{{\mathcal{P}_i}}(k,\mathcal{C}) + \zeta . w^{{\mathcal{P}_i}}_\Lambda(k,\mathcal{C}) + \xi . w^{{\mathcal{P}_i}}_\Delta(k,\mathcal{C}). \end{align*} $$ Los términos con los pesos modificados de esta forma se utilizan para generar nuevas consultas durante la prueba $i+1$. La convergencia final del algoritmo se alcanza luego de al menos $v$ cambios de fase si la efectividad no supera un cierto límite $\nu$ ($\nu < \mu$). Para evitar que los pesos de los términos crezcan indefinidamente es necesario que $\gamma + \zeta + \xi = 1$. El valor de $\gamma$ indica la cantidad de memoria que tendrá el sistema de una fase a la siguiente. Los valores de $\zeta$ y $\xi$ indican la cantidad de conocimiento que se conservará de una fase a la siguiente. Estas constantes afectan la velocidad de aprendizaje del sistema y su habilidad para conservar el foco de las búsquedas. El método propuesto es prometedor y la eficacia del mismo se evaluará en el Capítulo 5 utilizando una plataforma de evaluación especialmente diseñada para el análisis de sistemas de IR temáticos. Alcances y aplicacionesLa generación automática de consultas a partir de un contexto temático necesita de técnicas que tengan la habilidad de unir el contexto dado con las fuentes de material relevante. El problema de las coincidencias falso-negativas es una situación común que surge cuando el texto contiene un tópico similar pero el vocabulario de términos no coincide. Un problema complementario son las coincidencias falso-positivas, que aparecen cuando coinciden los términos del vocabulario pero los documentos pertenecen a tópicos diferentes. Estas dos situaciones problemáticas han sido identificadas desde hace mucho en la comunidad de IR como uno de los desafíos principales, y muchas propuestas han tratado de superar estas cuestiones con distintos grados de éxito. En este capítulo se ha propuesto un método que muestra un avance en el intento de solucionar los problemas mencionados anteriormente aprendiendo nuevos vocabularios. Se propuso utilizar los descriptores de tópicos para identificar aquellos términos que aparecen más frecuentemente en documentos asociados con el tópico dado. Estos términos no son necesariamente parte de la especificación de las necesidades de información del usuario, sin embargo, pueden encontrarse iterativamente analizando los conjuntos de documentos que se recuperan incrementalmente de la Web. Por otro lado, también se propuso utilizar los discriminadores de tópicos para identificar a aquellos términos que tienden a aparecer sólo en los documentos del tópico y muy pocas veces en documentos que no pertenecen a él. En el siguiente capítulo se presentará una Plataforma de evaluación sobre la cual se evaluará el método incremental propuesto, comparándolo con otros existentes en la literatura. El desarrollo de métodos que evolucionen consultas de alta calidad y recuperen recursos relevantes al contexto puede tener consecuencias importantes en la manera en la que los usuarios interactúan con la Web. Estos métodos pueden ayudar a construir sistemas para un amplio espectro de servicios de información:
ResumenEn este capítulo se presentó una de las contribuciones de esta tesis, un Método Incremental de Recuperación de Información basada en Contexto. Se comenzó con una breve introducción del método y de los problemas que tienen los sistemas de IR al no tener en cuenta el contexto en el cual se desarrollan las actividades de los usuarios. A continuación se hizo un análisis de los trabajos existentes en la literatura y se clasificaron los sistema de IR basados en contexto. Luego se introdujeron las nociones de descriptores y discriminadores de tópicos, que son los principios sobre los que se basaron los algoritmos presentados en esta tesis. Con ellos es posible mejorar la valoración de los pesos asignados a los términos que representan el contexto de un usuario y aumentar así el rendimiento de un sistema de recuperación. Luego se describió el método incremental propuesto, que es capaz de refinar consultas temáticas a partir de la técnica recién mencionada, adaptando el mecanismo de realimentación de relevancia para que considere el contexto temático del usuario. Finalmente, se presentó un análisis de los alcances y aplicaciones de la herramienta de recuperación propuesta. |
|||||||||||||||||||||
| Última actualización el Martes 12 de Junio de 2012 10:08 |

Caracterización Formal y Análisis Empírico de Mecanismos Incrementales de Bísqueda basados en Contexto por Carlos M. Lorenzetti se encuentra bajo una Licencia Creative Commons Atribución-NoComercial-CompartirDerivadasIgual 3.0 Unported.
Basada en una obra en bc.uns.edu.ar.