Caracterización Formal y Análisis Empírico de Mecanismos Incrementales de Búsqueda basados en ContextoTesis Doctoral en Ciencias de la Computación - Universidad Nacional del Sur por Carlos M. Lorenzetti Métodos de evaluaciónLa recuperación de información se ha vuelto una disciplina altamente empírica, por lo que para demostrar que un sistema con una técnica novedosa es superior a otro, necesita pasar por un riguroso proceso de evaluación sobre colecciones de documentos representativas. En este capítulo discutiremos las medidas de efectividad de los sistemas de IR y las colecciones que más se utilizan para este propósito.Colecciones de pruebaPara medir de forma estándar la efectividad de un sistema de IR necesitamos una colección de prueba en común y de acceso público. Las colecciones de prueba son una herramienta muy útil a la hora de medir y comparar algoritmos en IR. Consisten de corpus creados y compartidos por la comunidad de IR para promover una plataforma de prueba sobre la que se pueda medir la efectividad de los sistemas de recuperación. Una colección ideal está compuesta por:
Hacia fines de los años '40, uno de los principales problemas era la accesibilidad de los trabajos científicos que se habían desarrollado motivados por investigaciones des arrolladas durante la Segunda Guerra Mundial. En aquel momento había dos tipos convencionales de índices y dos técnicas de indexado. Un índice podía existir en la forma de un catálogo de tarjetas, como se encontraban en la mayoría de las bibliotecas, o alternativamente en forma impresa, por ejemplo, en compendios anuales de resúmenes de una revista. En cuanto a las técnicas de indexado, en Europa existía una tendencia al uso de sistemas de clasificación, mientras que en los Estados Unidos la práctica más usual era la utilización de los catálogos alfabéticos de temas. El modelo de clasificación bibliotecario era el dominante, y bajo él, un documento era clasificado/indexado por un ser humano. El resultado era una descripción corta del documento en un lenguaje más o menos formal. Cuando comenzaron a aumentar el número de publicaciones, en la forma de reportes técnicos, los índices y las técnicas de indexado fueron puestas a prueba y en los '50s hubo varios intentos por desprenderse de los sistemas convencionales. Los puntos de discusión en esa época eran: la forma particular del lenguaje de indexación, el tipo de análisis que llevaba a la construcción del mismo y su posterior aplicación en un documento y la granularidad, especificidad y divisibilidad de la representación. Otros tipos de discusiones eran más bien filosóficas, ya que los bibliotecarios trataban de imponer su visión del conocimiento humano y su forma de representarlo. El lenguaje natural, hasta ese momento, era considerado como algo separa do del sistema porque la clasificación formal trataba de alguna forma de evitar sus falencias. En este contexto, las experimentaciones empíricas eran una idea radical. Había una resistencia a ver a los sistemas de IR desde un punto de vista funcional, además de las dificultades que había para formular e implementar tales funcionalidades. CranfieldAlgunas investigaciones continuaron su curso estimuladas por [McN48] y algunos pequeños experimentos alrededor del mundo. El interés sería retomado en la Conferencia Internacional sobre Información Científica de 1958 [NSF58], pero para ese tiempo Cyril Cleverdon, bibliotecario del Colegio Cranfield de Aeronáutica, tenía sus propias ideas y comenzó el primero de dos proyectos Cranfield que fue publicado en 1962 [Cle62]. Este proyecto derribó las divisiones filosóficas que dominaban el área al someter a una competencia a cuatro esquemas de indexación. Cada uno de éstos eran ejemplos contrapuestos sobre cómo debía organizarse la información. El trabajo comparó la eficiencia de cada uno respecto del otro indexando 16000 documentos sobre Ingeniería Aeronáutica. Esos cuatro sistemas son descriptos a continuación. Clasificación Decimal Universal (UDC)Este sistema de clasificación bibliotecario fue desarrollado a finales del siglo XIX. Utiliza números arábigos y, como su nombre lo indica, se basa en el sistema decimal. Es un sistema jerárquico en donde el conocimiento se divide en diez clases, cada una de éstas se subdivide en partes y cada subdivisión se vuelve a subdividir hasta alcanzar el nivel de detalle deseado. Cada número se supone es una fracción decimal cuyo punto inicial no se escribe, pero para facilitar la lectura se agrega un punto cada tres dígitos. Por ejemplo, después de 00 `Fundamentos de la ciencia y de la cultura' viene las subdivisiones 001 a 009; debajo de 004 `Ciencia y tecnología de los ordenadores' están sus subdivisiones 004.1 a 004.9; debajo de 004.4 están todas sus subdivisiones antes que 004.5, por lo que después de 004.49 viene 004.5; y así siguiendo. Una ventaja de este sistema es que puede ser extendido indefinidamente, y cuando se introducen nuevas subdivisiones no hay que modificar las existentes. Catálogo alfabético de temasEs un sistema de clasificación en donde se describen los documentos por medio de términos que indican sobre qué trata el contenido del mismo. El proceso de indexado comienza con algún tipo de análisis sobre el tema del documento. Un indexador (una persona) debe identificar los términos que mejor expresan el contenido mediante la extracción de palabras que aparecen en el documento o utilizando palabras de algún vocabulario predeterminado. La calidad de los índices dependerá en gran medida de la experticia que tenga cada bibliotecario en el área. Esquema de clasificación facetadoEsta técnica analiza los temas y los divide en características. Permite que un objeto tenga múltiples clasificaciones, y habilita a un usuario a navegar a través de la información por distintos caminos, que se corresponden con los distintos ordenamientos de las características. Estas ideas se contraponen con los sistemas jerárquicos como el UDC, en donde sólo hay un único orden predeterminado. Este sistema se originó a partir de la Clasificación por dos puntos, publicada por primera vez en 1933 [Ran33]. Se le da este nombre porque utiliza signos de puntuación (como “:”, “;”) para separar las facetas. El sistema representa los objetos a partir de 42 clases principales, divididas en 5 categorías fundamentales: personalidad, material, energía, espacio y tiempo. Por ejemplo, supongamos que tenemos un libro titulado “La administración de la Educación Elemental en el Reino Unido en los '50s” [Gar84]. Para este tópico, “educación” es la clase principal y se representa con una letra `T'. La característica distintiva, o personalidad, es “Elemental”, representada por el número `15'. Al no existir un material se introduce directamente un signo “:”. La acción que ocurre respecto de la clase principal, o energía, es “administración”, representada por un número `8'. El espacio, o ubicación geográfica, viene precedida de un signo “.”, en este caso “Reino Unido”, representado con un número `56'. Luego se continúa con una comilla simple que indica el comienzo del campo tiempo, en este caso 1950, que se representa con `N5'. Finalmente tenemos, T15:8.56'N5. Sistema de unitérminos de indexado coordinadoEste sistema está basado en la implementación de unitérminos y la aplicación de lógica booleana (Subsección 2.1.1). Los unitérminos son términos individuales que son seleccionados por los indexadores para representar las distintas características de los documentos. Mortimer Taube, un bibliotecario que trabajaba para el gobierno de los Estados Unidos, analizó cerca 40000 encabezados temáticos en un gran catálogo de tarjetas y encontró que tales encabezados eran combinaciones de, “sólo”, 7000 palabras distintas. Entonces propuso utilizar estas palabras como términos de indexado que pueden ser coordinados, o interconectados, en la etapa de búsqueda [Cle91]. Los unitérminos pueden considerarse, en cierto sentido, como las palabras clave de hoy en día ya que ambos están derivados del documento original y no se hace ningún control del vocabulario. Típicamente se utilizan varios unitérminos para representar un único documento, como con las palabras clave. Para la realización de cada índice se emplearon distintas personas expertas en cada sistema, los cuales fueron implementados con tarjetas. La evaluación se llevó a cabo con 1200 consultas pero, para evitar los juicios de relevancia, las consultas fueron creadas a partir de algún documento dentro de la colección. Se consideró que evaluar la relevancia de cada documento para cada consulta sería una tarea excesivamente larga. Algunos trabajos anteriores habían intentado obtener juicios de relevancia conciliando las opiniones de distintos jueces, pero lo encontraron también muy difícil. Los sistemas fueron comparados entonces de acuerdo a si recuperaban o no el documento “fuente”. Sin embargo, este método fue severamente criticado por tres razones principales:
Los resultados mostraron que los cuatro sistemas alcanzaron una eficiencia en el rango del 74% al 82%, con el sistema de unitérminos en primer lugar y la clasificación facetada en el último. Se hizo un análisis detallado sobre las causas de los errores en la localización del documento deseado y la mayoría se debieron a errores humanos en alguna de las etapas del proceso de indexación o recuperación. Cranfield 2Las discuciones que originó Cranfield 1 llevaron a la creación de un segundo proyecto. La transición a la versión 2 fue un gran salto en cuanto al contenido y a la metodología [CMK66]. En cuanto al contenido, la atención continuó en los “lenguajes de indexación”: lenguajes artificiales creados para permitir representar de manera formal a los documentos y a las consultas. Se estudió meticulosamente el proceso de construcción de un lenguaje evaluándose 8 que utilizaban términos simples (unitérminos), 15 basados en conceptos y 6 basados en términos fijos (diccionarios). Sin embargo, el logro más importante de Cranfield 2 fue el de definir la noción de metodología de experimentación en IR. Las ideas básicas sobre recolectar los documentos y las consultas se habían heredado de la primera versión del proyecto, pero el cambio más grande ocurrió con la noción de respuesta correcta. Los documentos elegidos para responder a cada una de las consultas se eligieron con una variedad de métodos, incluyendo la búsqueda manual y una forma de indexado basado en citas. La intención fue la completitud, es decir, descubrir todos (o casi todos) los documentos relevantes dentro de la colección. La experiencia les había demostrado que no eran esenciales demasiados documentos en la colección, pero si lo era tener todos los juicios de relevancia de todos los documentos para todas las consultas. En esta oportunidad se les enviaron cartas a aproximadamente 200 autores de artículos recientes, para que describieran en forma de pregunta el problema sobre el que trataban sus trabajos, y que agregaran preguntas adicionales que surgieron en el curso de la investigación. Entonces también se les indicó que le dieran una puntuación de 1 a 5 a cada una de las referencias que citaron en sus trabajos. El resultado fueron 1400 documentos y 279 consultas. Cada consulta fue analizada para cada documento por un grupo de estudiantes y los documentos que se consideraron relevantes fueron reenviados al autor de la pregunta para el juicio final. El mejor rendimiento fue alcanzado por los lenguajes que utilizaban términos simples. Aunque hoy en día casi todos los motores de búsqueda se basan en búsquedas por términos del lenguaje natural, esta conclusión fue impactante en aquel entonces. Hay que destacar que, incluso en este proyecto, los experimentos fueron realizados sin la ayuda de computadoras. Por último, en los comienzos del proyecto, se tenía la idea de encontrar que alguno de los índices utilizados mejoraría la cobertura o la precisión, llegando a la conclusión de que ninguno era particularmente mejor que otro. También se observó que, en general, tiende a existir una relación inversa entre la cobertura y la precisión. SMARTEl sistema SMART [Sal71] es un sistema de los años '60s con el que se realizaron los experimentos más importantes de la época en IR utilizando computadoras. Liderado por Gerard Salton, se desarrolló mayoritariamente en la Universidad de Cornell hasta su finalización en los años '90s. Muchas de las ideas que se desarrollaron allí se utilizan ampliamente hoy en día en los motores de búsqueda. En particular, pueden destacarse: la utilización de métodos completamente automáticos basados en el contenido de los documentos; la noción de función de ordenamiento (para medir el grado de relevancia de un documento) y su posterior ubicación en una lista que se muestra al usuario. Es importante mencionar que esto último, que estuvo incluido en SMART desde su comienzo, no apareció en ningún sistema comercial hasta finales de los '80s y terminó de triunfar recién a mediados de los '90s con los motores de búsqueda web. El sistema utilizó un modelo de representación vectorial (Subsección 2.1.2) y el sistema de pesos TF-IDF ideado por Spärck Jones [SJ72]. La idea de realimentación de relevancia (Subsección 2.2.2) también fue introducida en el sistema por Rocchio [Roc71b]. Los primeros experimentos se realizaron sobre pequeñas colecciones de prueba (decenas o cientos de documentos) creadas por ellos mismos o reutilizadas de otros experimentos. En particular utilizaron la colección Cranfield cuando estuvo disponible para su acceso electrónico. En principios de los '80s comenzaron a utilizar, y a su vez a construir, algunas colecciones más grandes. Hay que tener en cuenta que en el año 1973 una sola corrida sobre la colección Cranfield 2 tomaba 10 minutos a un costo monetario altísimo. MEDLARSEl Servicio de Búsqueda por Demanda (MEDLARS) fue uno de los primeros sistemas de recuperación bibliográfica de literatura médica computarizado. Desde 1879 la Biblioteca Nacional de Medicina (NLM) editaba un índice bibliográfico anual, pero no fue hasta los '40s que divisaron nuevas tecnologías que acelerarían el proceso. En enero de 1959 comenzaron a editar un índice mensual llamado Index Medicus con la ayuda de un proceso mecanizado de tarjetas. En 1960 comenzaron a analizar la posibilidad de utilizar una computadora, pero dados los costos que implicaba, el proyecto fue largamente estudiado. Con su uso se deberían reducir los tiempos de producción de las ediciones mensuales del índice y la búsqueda y recuperación de bibliografía. El sistema de indexado utilizado fue el Catálogo Alfabético de Temas, descripto en la Subsección 3.1.1, que para el área de medicina se llama MeSH. Por otro lado, para el almacenamiento de la información se utilizaron cintas magnéticas de acceso secuencial. El sistema estuvo funcional para 1964. El aporte más grande de este proyecto estuvo en las búsquedas por demanda. Un investigador que estuviera interesado en buscar determinada bibliografía debía contactar al experto en búsquedas que trabajaba en el NLM personalmente o por carta. Las consultas eran creadas exclusivamente sobre los términos de indexado del lenguaje MeSH y utilizaban lógica booleana (Subsección 2.1.1). El experto creaba las consultas en base a su interacción con el usuario, lo cual requería un gran entrenamiento. La salida era un conjunto de referencias impresas sin ningún orden en particular. Como puede notarse, no había una interacción directa entre los usuarios y la computadora, por otro lado, el proceso era caro y el tiempo de obtención de los resultados oscilaba entre 3 a 6 semanas. Es por eso que en los '70s se implementó un nuevo sistema de formulación de consultas on-line llamado MEDLINE (MEDLARS onLINE) que se mantiene hasta nuestros días. TRECDesde comienzos de los años '60 y por un período de 20 años, Karen Spärck Jones condujo una serie de experimentos en clustering y ponderación de términos. A diferencia de Cleverdon, e incluso de otros investigadores de su época, no construyó su propia colección de prueba. Sus primeros experimentos se basaron únicamente en la versión electrónica de Cranfield 2 [SJ71] y fue una de las primeras en darse cuenta de los beneficios y de las dificultades de reutilizar colecciones de prueba construidas por otros investigadores. Durante ese período inventó una forma de ponderar términos basada en el número de documentos en los que aparecen (IDF, [SJ72]). Luego el equipo de SMART combinó esta métrica con la frecuencia del término dentro del documento (TF) para crear una de las medidas que más influyó en los algoritmos de ponderación de términos y de ordenamiento de documentos de la siguiente generación (Ecuación 2.4). Desde mediados de los '70s hasta entrados los '80s lideró los esfuerzos para depurar los estándares básicos y para mejorar los métodos y los datos de experimentación en IR [SJvR75]. También editó un libro con varios autores del área [SJ81], que fue la única fuente coherente de consulta a la hora de planificar y ejecutar un experimento en IR hasta, quizás, la edición del libro sobre las experiencias de TREC en 2005 [VH05]. Otro resultado de su trabajo fue el diseño de una colección de prueba estándar, ya que hasta la época sólo existían colecciones que habían sido creadas para llevar a cabo un experimento específico, pero que eran reutilizadas en otros experimentos. El estudio incluyó un minucioso análisis sobre los aspectos más importantes de la preparación de los datos, como por ejemplo, la técnica de selección para obtener los juicios de relevancia sobre una gran colección de datos [SJvR75]. Contando con pocos recursos para sus proyectos el desarrollo se detuvo, hasta que a comienzos de los '90 se puso en marcha el proyecto TREC. La Conferencia de Recuperación de Información (TREC) es un conjunto de workshops anuales enfocados en las distintas áreas de IR. El proceso en su conjunto está dirigido por el Instituto Nacional de Estándares y Tecnología de los Estados Unidos (NIST), pero cada workshop en particular (track) es en general organizado por los grupos de investigación participantes. En la Tabla 3.1 se muestran los distintos tracks y su evolución a lo largo de los años [VH05,VB04,VB05,VB06,VB07,VB08,VB09]. Como se dijo más arriba no existía un esfuerzo conjunto de parte de los grupos de investigación por utilizar los mismos datos de prueba o, por comparar los resultados entre sistemas de IR. La intención de estas comparaciones no era mostrar que un sistema era mejor que otro, sino poder utilizar una variedad mucho mayor de técnicas, sobre todo al momento de proponer nuevas. Por otro lado, también hacía falta una colección de un tamaño mucho más realista, ya que como se dijo, la colección Cranfield sólo alcanzaba a los miles de documentos. Había que ser capaz de demostrar que las técnicas eran aplicables a grandes colecciones de documentos. Es por esto que en 1990 se le encomienda al NIST construir una colección de cerca de un millón de documentos. La primera conferencia se llevó a cabo en 1992 sobre la base de una colección de aproximadamente 2 GB de artículos de diarios y documentos gubernamentales. El track central de las primeras conferencias se llamó track ad hoc, el cual medía la capacidad de un sistema para recuperar listas precisas y completas de documentos ordenados (éste fue el principal cambio respecto de Cranfield). Estas listas de resultados se generan en respuesta a determinadas consultas que fueron creadas conjuntamente con la colección y suele asumirse que son temáticas (documentos acerca de X). En TREC se las llama `tópicos'. Un `tópico' tiene un título corto (el cual puede usarse como consulta) e información adicional acerca del conocimiento que supuestamente se necesita. Esta descripción contiene reglas explícitas para juzgar la relevancia de los documentos. Un ejemplo de título y descripción son: “Boeing 747” y “Aerolíneas que utilizan actualmente aviones Boeing 747”. El proceso de creación de un nuevo track incluye la producción de la colección de documentos, los tópicos y el conjunto de juicios de relevancia (sobre esto se hablará en particular más adelante). Luego la colección se distribuye entre los participantes, cada uno la indexa y corre experimentos sobre sus sistemas de búsqueda. Algunos resultados de estos experimentos son enviados al NIST en donde se evalúa su relevancia. Finalmente se realiza la conferencia, los organizadores escriben un reporte sobre los resultados de cada track y los equipos participantes escriben reportes técnicos sobre sus sistemas. También pueden llegar a escribirse ediciones especiales de alguna revista con los resultados de una conferencia [Har95,Voo00a] o de un track en particular [HO01,Rob02].
Juicios de relevancia manualesCrear colecciones de prueba presenta muchos desafíos metodológicos, pero el mayor incumbe al conjunto de documentos a los que se le evaluará la relevancia. Una colección ideal está compuesta de un conjunto de documentos, un conjunto de consultas y una lista que indica qué documentos son relevantes para esas consultas. Los documentos y las consultas suelen ser relativamente fáciles de obtener, sin embargo, los juicios de relevancia son algo costoso. Las colecciones de los '60s, '70s y principios de los '80s eran pequeñas: no más de 3 MB de texto, por lo que los juicios se realizaban de manera exhaustiva, examinando cada documento para cada consulta. Sin embargo, si su tamaño crece hasta tamaños más realistas se necesita un esfuerzo considerable, evitando que cada juez pueda analizar todos los documentos de manera completa. Ya en los '70s Spärck Jones y van Rijsbergen notaron que examinar cada documento de manera exhaustiva no era escalable y propusieron un método no exhaustivo. En el reporte de 1975 [SJvR75] y en los siguientes [SJB77,GSJ79] describieron la construcción de una colección de prueba `ideal'. El uso del pooling fue propuesto como una forma eficiente de encontrar los documentos relevantes dentro de una gran colección de documentos. Se asumió que dentro de este pool, o fondo común, se encontrarían casi todos los documentos relevantes. Para crear los juicios de relevancia se tomaría una muestra aleatoria del pool de documentos. Como se describe en [SFW83], este método se utilizó para recopilar los juicios de relevancia de la colección Inspec de 5.5 MB. Cada consulta se procesó con siete métodos distintos y luego todos los documentos recuperados fueron mezclados, eliminando los repetidos. El pool resultante fue examinado por los asesores de relevancia. TREC utiliza este sistema y es uno de los más utilizados. Aquí sólo se evalúan los $k$ mejores documentos enviados por cada uno de los $n$ grupos participantes. Si $k$ y $n$ son grandes se considera que el conjunto de documentos relevantes juzgados es representativo del conjunto ideal, y luego útil para ser usado en la evaluación de los resultados de un proceso de recuperación. Por ejemplo, en los experimentos del track ad hoc de TREC-6 [HV97] se utilizaron valores de $k=100$ y $n=30$, lo que implicó, para las 50 consultas temáticas, unos 60000 juicios. El número total de juicios requeridos si se utilizaba un examen exhaustivo hubiera sido de 500000. Este método tiene críticas y hay estudios acerca de la completitud de este subconjunto de documentos y sobre la consistencia en los juicios de relevancia entre los distintos jueces [Voo98,Zob98]. Se mostró que es necesario tener: suficientes tópicos para lograr una buena estabilidad al promediar los juicios de todos los jueces, suficientes documentos en los subconjuntos de documentos para asegurar que se encuentren los más relevantes, y suficientes participantes para tener variedad en el conjunto final. Juicios de relevancia automáticosMotivaciónLa forma no exhaustiva de evaluación que se presentó en la sección anterior también tiene problemas a la hora de escalar o cambiar la colección de documentos, por lo que se han desarrollado métodos que intentan reducir los problemas de escalabilidad. Una forma es utilizar colecciones o consultas que contengan información semántica que ayude a la evaluación de la relevancia. Ciertas colecciones de noticias incluyen etiquetas de categorías codificadas manualmente. Con ellas pueden ser entrenados y probados sistemas de clasificación de manera automática, para luego ser utilizados en la evaluación de algoritmos de ranking y métodos de representación de texto [Lew92]. Otra posibilidad es crear consultas para las cuales sólo existan pocos documentos relevantes en la colección. En [SWS97] se construyó una colección de noticias en la cual las consultas se referían a eventos con una fecha de inicio, lo que hizo que los evaluadores pudieran limitarse sólo a los documentos a partir de esa fecha. Las consultas pueden limitarse más aún hasta que sólo exista un documento relevante; esta clase de búsqueda se llama de ítem conocido y fueron usadas en las primeras ediciones de TREC [GVSSJ97]. A pesar de estos intentos la mayor parte de las colecciones disponibles siguen el método de pooling. Es por esto que [Zob98] se interesó en maximizar el número de documentos relevantes encontrados y notó, como podría ser lógico pensar, que la cantidad de documentos relevantes para cada consulta no es constante y que esto afecta la eficiencia del proceso de análisis de relevancia. Teniendo en cuenta la contribución de cada participante al pool de consultas, en [CPC98] notaron que ciertos sistemas contribuían con más documentos relevantes que otros, por lo que propusieron un sistema de pooling que juzga primero a los documentos de los mejores sistemas. Este método fue utilizado hasta alcanzar el 50% de los documentos examinados en TREC-6 y fue correlacionado con éste alcanzando una distancia de Kendall [Ken38] de $\tau = 0.999$. Reduciendo los documentos al 10% de los examinados en TREC la correlación se redujo muy levemente, alcanzando un valor de $\tau = 0.990$. Estas ideas también fueron implementadas luego en [CA05]. Puede verse que ambos sistemas son extremadamente similares y, por lo tanto, que la forma de hacer pooling en TREC es altamente ineficiente. Esta conclusión se basa en [Voo98] y en [Voo01] en donde se muestra que una correlación de al menos $0.9$ implica que ambos sistemas son equivalentes. Por otro lado también se propuso una nueva forma de hacer pooling que incluye una combinación de búsqueda, evaluación y reformulación de consultas que dieron en llamar ISJ [CPC98]. Para cada consulta los jueces debían realizar la búsqueda con consultas que refinarían de acuerdo a sus criterios personales hasta que no encontraran más resultados relevantes. La correlación encontrada al realizar la comparación fue de $0.89$, muy cercana al límite antes mencionado. Los autores encontraron que esta correlación ligeramente inferior pudo deberse a las diferencias de opiniones de los jueces de ISJ y los de TREC en cuanto a qué documentos eran relevantes y cuáles no. En el track Filtering de TREC-2002 [SR03], con el objetivo de realizar un proceso de evaluación más exhaustivo, se implementó un sistema de pooling que utilizaba refinamiento de consultas pero de forma automática. Se crearon conjuntos iniciales de documentos que se les dieron a evaluar a los jueces. A partir de estos juicios se realimentó esta información en los sistemas de recuperación y se obtuvieron nuevos documentos para evaluar. Este proceso se realizó durante cinco iteraciones o hasta que no se encontraran más documentos relevantes. Analizando los problemas de crear continuamente nuevas colecciones de documentos, se propuso mantener los conjuntos de TREC existentes para limitar el impacto de estos cambios, ya que el mantenimiento es más sencillo que la búsqueda de nuevos tópicos y la realización de nuevos juicios de relevancia [Sob06]. Finalmente en [SJ04] se analizaron métodos para producir colecciones de prueba de forma automática, sin utilizar pooling, encontrando altas correlaciones con las colecciones de TREC. Estos sistemas de evaluación automática son muy utilizados en dominios en los que la evaluación manual requeriría un esfuerzo prohibitivo [GLLV05]. Las técnicas de evaluación automática en IR podrían clasificarse en dos grupos: Inferencia automática y Fuentes externas de relevancia. Inferencia automáticaLas técnicas dentro de este grupo infieren los juicios de relevancia a partir de los documentos recuperados. Algunos métodos muestrean aleatoriamente los conjuntos de documentos recuperados basándose en estadísticas conocidas acerca de la distribución típica de los documentos relevantes, tomándolos como pseudorelevantes. Este tipo de técnica es muy utilizada en conjunto con la Realimentación de relevancia sin supervisión, vista en el Capítulo 2, en donde la forma más básica de seleccionar términos potencialmente útiles es elegirlos de los $k$ mejores documentos recuperados por una consulta. Algunos métodos también utilizan los $k'$ peores documentos recuperados como una fuente de información para los términos irrelevantes. Las distintas variantes existentes han surgido porque distintos autores han propuesto diversas técnicas para la asignación de los pesos de los términos. En [SNC01] se construyó un modelo de distribución de los documentos en el pool de TREC para seleccionar documentos aleatoriamente y crear un conjunto de documentos pseudorelevantes. Esto se hizo para tratar de probar la hipótesis de que ``los rankings de los sistemas de IR son robustos, aún si los documentos relevantes se eligen al azar del conjunto de documentos recuperados'', aludiendo al desacuerdo existente en los juicios de los jueces de la mencionada competencia. Los resultados obtenidos mostraron cierta correlación con los rankings de algunos equipos participantes, pero poca con los mejores sistemas. Otros sistemas utilizan funciones de similitud entre los documentos recuperados y la consulta [SL02]. Estas funciones tienen el propósito de encontrar términos que coocurran con los términos de la consulta en el mismo documento, en el mismo párrafo, en la misma sentencia o en una determinada ventana de palabras. La efectividad del sistema de IR se verá fuertemente afectada por la elección de la función de similitud [KC99]. Algunas medidas de similitud fueron mencionadas en la Sección 2.3. Fuentes externasEn este grupo se encuentran los métodos que utilizan fuentes de información externas para ayudar en la tarea de inferencia. Algunos utilizan la información de los clicks del usuario (tuplas que consisten de una consulta y un resultado elegido por el usuario) para evaluaciones automáticas. Sin embargo, en estos datos existe un sesgo inherente: los usuarios tienden a hacer click en los documentos mejor rankeados, sin importar su calidad [BFJ96]. De cualquier manera, en [JGP+05] se encontró que estos datos pueden utilizarse exitosamente para inferir preferencias relativas entre documentos. Para realizar evaluaciones automáticas, otras investigaciones han hecho uso de taxonomías tales como el ODP (referido también como DMOZ), el directorio de Yahoo! y Looksmart [HGKI02,SMP05]. Estas taxonomías dividen a una porción de la Web en una jerarquía de categorías, con páginas en ellas. Cada categoría tiene un título y un camino que representa su lugar en la jerarquía. Típicamente también existen títulos en las páginas, ingresados por editores de la taxonomía, que no se corresponden necesariamente con los títulos originales de las páginas. La aparición de taxonomías online mantenidas por personas, como ODP, permiten una forma de evaluación automática. Se basa en tomar una gran muestra de las consultas de la Web actual y para cada una de ellas recolectar conjuntos de documentos pseudorelevantes en la taxonomía. En [BJCG03] se analizan métodos para la evaluación de motores de búsqueda web de forma automática utilizando ODP. Se asume que los editores humanos aseguran un contenido de alta calidad y relevante dentro del directorio. Se tiene un conjunto de consultas que se mapean a documentos de la colección con algún criterio, en particular se proponen dos técnicas, la primera exige una coincidencia exacta de la consulta con el título de la página y la segunda una coincidencia exacta con el título de la categoría a la que pertenece la página, permitiendo esto último la existencia de más documentos relevantes. Luego esas consultas se ejecutan en los motores de búsqueda y se registra la ubicación del documento en los resultados. Como métrica de comparación se utilizó la media de esa ubicación para todas las consultas. Mostraron que el directorio utilizado no introduce un sesgo significativo en la evaluación y que las distintas consultas no afectan a la estabilidad de la métrica. Aunque la comparación con juicios de relevancia manuales mostró una correlación moderada, este tipo de métodos automáticos tiene la ventaja de poder evaluar muchas más consultas que los métodos manuales, abarcando una gran diversidad de tópicos. En [HGKI02] utilizaron ODP como una variante de estudio de usuarios precompilado para desarrollar un método automático de evaluación de estrategias de representación de documentos. Se tuvieron en cuenta tres características de una página web $u$ a la hora de representarla en un espacio vectorial:
MétricasLa eficiencia de los sistemas de recuperación de información se mide comparando su rendimiento en un conjunto común de consultas y documentos. Para evaluar la confianza de tales comparaciones suelen utilizarse los test de significancia (pruebas t o de Wilcoxon), que muestran que las diferencias observadas no son por azar. Desde Cranfield se han utilizado seis métricas principales:
Se podría decir que los puntos 1 a 4 son fácilmente cuantificables. La COBERTURA y la PRECISIóN son las métricas que se conocen como la efectividad de un sistema de recuperación. En otras palabras es una medida de la habilidad del sistema para recuperar documentos relevantes y a la vez evitar los irrelevantes. Se asume que cuanto más eficiente es un sistema más satisfará al usuario, y también se asume que la precisión y la cobertura son métricas suficientes para cuantificar esa efectividad. Ha habido mucho debate sobre si de hecho la precisión y la cobertura son cantidades apropiadas de usar como métricas de la efectividad. Una alternativa han sido la cobertura y el fall-out (la proporción de los documentos irrelevantes recuperados). Sin embargo, todas las alternativas siguen necesitando el cálculo de alguna forma de relevancia. La relación entre las distintas medidas y su dependencia de la relevancia serán explicadas luego. Las ventajas de basar la evaluación en la precisión y la cobertura son:
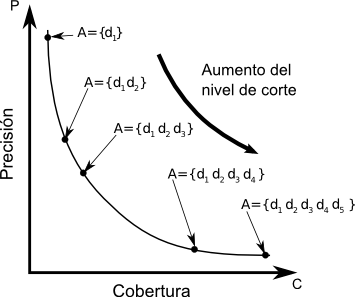
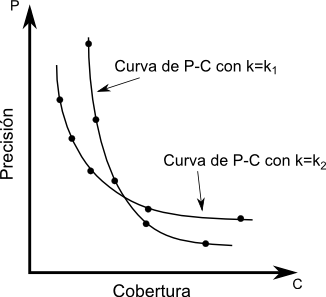
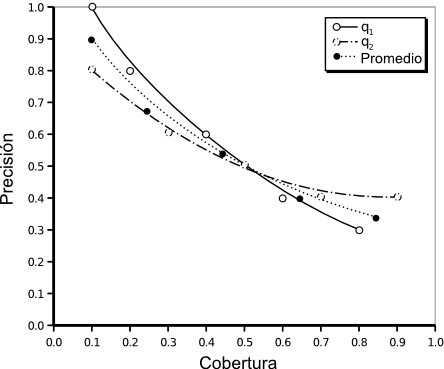
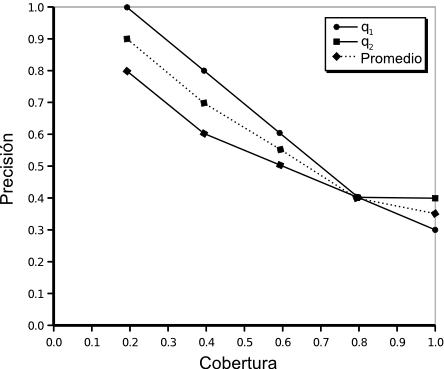
Muchas veces la técnica utilizada para medir la efectividad de un sistema de recuperación se ve influenciada por la estrategia de recuperación que se adopta y por la forma que tiene su salida. Por ejemplo, cuando la salida es un conjunto ordenado de documentos un parámetro obvio es la posición de cada uno de los documentos recuperados. Utilizando esta posición como un límite de corte pueden calcularse los valores de precisión y cobertura para cada valor de corte. Luego, los resultados pueden resumirse en una curva suave que una dichos puntos en un gráfico de precisión-cobertura (P-C, fig:p-r-graph). El camino a lo largo de la curva sería interpretable como la variación de la efectividad en función del valor de corte. Desafortunadamente siguen existiendo preguntas que esta métrica no es capaz de responder, como ser, ¿cuántas consultas son mejores que la media y cuántas peores? A pesar de esto, explicaremos este tipo de medidas de la efectividad dado que son las más comunes. Antes de continuar es necesario examinar el concepto de relevancia, ya que está detrás de las medidas de efectividad. RelevanciaLa relevancia es un concepto subjetivo, ya que distintos usuarios pueden diferir acerca de cuáles documentos son relevantes y cuáles no para ciertas consultas. Sin embargo estas diferencias no son lo suficientemente grandes como para invalidar experimentos que se han hecho con colecciones de documentos estándar. Las consultas se crean generalmente a partir de la necesidad de información de usuarios con conocimientos en el área. Los juicios se realizan por un grupo de expertos en esa disciplina. Entonces ya tenemos cierto número de consultas para las cuales se conocen las respuestas `correctas'. Una de las hipótesis generales dentro del campo de la IR es que si una estrategia de recuperación se comporta bastante bien para un gran número de experimentos entonces es probable que se desempeñe bien en una situación real, en donde la relevancia no se conoce a priori. La relevancia es uno de los conceptos más importantes, sino el ``fundamental'', en la teoría de la IR [CL01]. El concepto surge de considerar que si un usuario de un sistema de IR tiene una necesidad de información, entonces alguna información almacenada en algunos documentos en una colección pueden ser ``relevantes'' a esta necesidad. En otras palabras, la información que se considerará relevante para la necesidad de información del usuario es aquella que puede ayudarlo a satisfacerla. Cualquier otra información que no se considere relevante se considera ``irrelevante'' a esa misma necesidad de información. Esto es una consecuencia de aceptar que el concepto de relevancia tiene dos posibles valores. Existe también un concepto de relevancia que puede decirse ser ``objetivo'' y merece mención. Una definición lógica de relevancia fue introducida por Cooper en 1971 [Coo71]. La definición de relevancia lógica para IR se hizo por analogía con el mismo problema en los sistemas de respuesta a consultas. Esta analogía no llegó más allá de considerar consultas del tipo si-no (verdadero-falso). La relevancia fue definida en términos de consecuencia lógica y para hacer esto las consultas y los documentos fueron definidos por conjuntos de sentencias declarativas. Una consulta si-no se representa con dos declaraciones formales, llamadas declaraciones de componentes, de la forma $p$ y $\neg p$. Por ejemplo, si la consulta es `¿El nitrógeno es un gas noble?' las declaraciones en lenguaje formal serían `El nitrógeno es un gas noble' y `El nitrógeno no es un gas noble'. Las consultas más complicadas, como las del tipo ¿cuál? o ¿qué pasa si? pueden transformarse a esta forma [Bel63,BS76]. Aunque inicialmente la relevancia lógica se definió sólo para sentencias, puede ser fácilmente extendida para su aplicación en documentos. Un documento es relevante para una necesidad de información si y sólo si contiene al menos una sentencia que sea relevante para esa necesidad. El autor también intentó abordar el problema de los grados de relevancia, o como el dijera: ``los tonos de grises en lugar del blanco y negro''. Precisión y CoberturaAhora dejamos las especulaciones acerca de la relevancia y volvemos a la medición de la efectividad. Asumimos una vez más que la relevancia tiene su significado usual de `pertenencia a un tópico' y `aptitud', esto es, el usuario es el que determinará si un documento es relevante o no. La efectividad es estrictamente una medida de la habilidad del sistema para satisfacer al usuario en términos de la relevancia de los documentos recuperados. Inicialmente, veremos cómo medir la efectividad en términos de la precisión y la cobertura. En la Tabla 3.2 se muestran los distintos conjuntos en los que se puede dividir la salida de un sistema de IR. A partir de ella pueden derivarse un gran número de medidas de efectividad a partir de esta tabla. Algunas son: $$\begin{align*} {\rm Precisi\acute{o}n} = P & = \frac{|{R \cap A}| }{|{A}|}\text{,}\\ {\rm Cobertura} = C & = \frac{|{R \cap A}|}{|{R}|}\text{,}\\ {\rm Cutoff} & = \frac{|{A}|}{N}\text{,}\\ {\rm Fallout} & = \frac{|{\bar R \cap A}|}{|{\bar R}|}\text{.} \end{align*}$$Se pueden construir tablas a partir de cada pedido $q$ que se envía al sistema de recuperación y a partir de estas se calculan los valores de precisión-cobertura. Si la salida del sistema depende de algún parámetro (digamos $k$), como puede ser la posición de los documentos o el nivel de coordinación (el número de términos que una consulta tiene en común con un documento), pueden construirse tablas para cada valor de ese parámetro y obtener un valor distinto de P-C que puede notarse por el par ordenado ($P(k)$, $C(k)$). A partir de estos pares ordenados se construye un gráfico de P-C, en el cual los puntos generados para un $k$ dado se unen para formar una curva de P-C. Todas las curvas se promedian para medir el rendimiento conjunto del sistema. Técnicas basadas en promediosAdemás de la técnica explicada más arriba, existen dos alternativas de promediado de curvas. Cuando se hace una recuperación por nivel de coordinación se adopta la microevaluación [Sal66,Roc66,Roc71a]. Sea $Q$ el conjunto de pedidos de búsqueda, entonces el número de documentos relevantes recuperados para $Q$ es: La Figura 3-3 muestra gráficamente que sucede cuando se combinan dos curvas individuales de P-C de esta manera. Los datos a partir de los que se generaron estas curvas pueden verse en la Tabla 3.3. Una alternativa de promediado también es la macroevaluación [Sal66,Roc66,Roc71a], la cual es independiente de cualquier parámetro del sistema. En este caso, se miden para cada consulta, los valores de precisión (cobertura) para determinados valores fijos o estándar de cobertura (precisión), como por ejemplo, los valores de precisión alcanzados cuando se logra una cobertura de $\{0.2, 0.4, 0.6, 0.8, 1\}$. En la fig:macroevaluation se muestra un ejemplo. El valor promedio de precisión (cobertura) se calcula simplemente como el promedio de los valores de precisión (cobertura) de cada consulta para cada valor de cobertura (precisión). Como puede verse, el promediado de valores es necesario, pero también trae problemas, porque puede existir una gran varianza en los puntos, lo que obliga a un análisis de significatividad estadística.
La precisión también puede calcularse en determinados puntos de corte de la lista ordenada de documentos que devuelve un sistema de recuperación. La Precisión a 10 documentos recuperados ($P@10$) [HC01] se obtiene calculando la precisión de un conjunto de resultados considerando solamente los 10 primeros resultados de la lista ordenada. Esta es una métrica popular porque refleja el número de respuestas por defecto que devuelven la mayoría de los motores de búsqueda web. En forma más general, puede hablarse de Precisión a un rango k. Dado un pedido $q$, el sistema devuelve una lista de documentos $D_q = \{d_1, \dots, d_m\}$, entonces se define la Precisión a un rango como: MAPLa Precisión Promedio Media (MAP) es una de las métricas más ampliamente usadas y nos da una representación numérica de la efectividad de un sistema [BV05]. Geométricamente esta métrica es equivalente al área debajo de la curva de P-C. Para calcular la precisión promedio media sobre una única consulta se promedian los valores de precisión que se obtienen luego de recuperar cada documento relevante. Luego la MAP es la media sobre un conjunto de consultas. Esta métrica ha mostrado ser estable al variar el tamaño del conjunto de consultas [BV00] y al ruido introducido por las variaciones de los juicios de relevancia [Voo00b]. Formalmente, si se tiene un conjunto de consultas $Q$, y el resultado que devuelve el sistema de recuperación para $q_i \in Q$ es la lista ordenada de documentos $D_{q_i} = \{d_1, d_2, \dots, d_{m}\}$, entonces se define la MAP para una consulta como: Esta métrica necesita tener disponible la información de relevancia de forma completa, o sea, haber evaluado para cada consulta si cada documento en la colección es relevante o no. El principal problema de MAP es que no puede interpretarse fácilmente, ya que si por ejemplo tenemos un $\mathit{MAP}=0.4$ no sabremos qué significa con exactitud, pero si tenemos una $P@10 = 0.4$ sabremos que obtuvimos cuatro documentos relevantes dentro de los diez primeros recuperados. Como se dijo en la sec:juicios_man, es un problema obtener juicios de relevancia completos a medida que el tamaño de las colecciones de prueba crece. Al utilizar pooling aumenta el número de documentos que no son evaluados por los jueces (considerados irrelevantes por la métrica). Por esto en [BV04] se define la métrica $\mathit{bpref}$, que utiliza información sobre los documentos no relevantes juzgados para generar una función que indica qué tan frecuentemente se recuperan documentos relevantes antes que los irrelevantes. $$ \begin{align*} \mathit{bpref}(q) = \frac{1}{|{R_q}|}\sum\limits_{d_j\in R_q}{\left(1-\frac{\text{# de docs irrelevantes encima de }d_j}{|{R_q}|}\right)}\text{.} \end{align*} $$Si se cuenta con la información de relevancia de toda la colección, esta métrica y $\mathit{MAP}$ muestran una alta correlación [BV04]. Sin embargo, $\mathit{bpref}$ se comporta mejor en los casos de juicios incompletos. Recientemente han surgido algunas críticas a esta métrica y en [Sak07] se proponen otras alternativas. Medidas compuestasEn muchas ocasiones es útil y necesario contar con una medida que represente la efectividad de un sistema y que posea una sola dimensión. Ya en 1967 Swets enunciaba, entre las propiedades de una métrica de rendimiento de recuperación, la necesidad de un único número en lugar de par de números que pueden llegar a covariar de formas poco claras, o en lugar de una curva construida a partir de una tabla [Swe67]. Esto permite el ordenamiento y la comparación de sistemas en términos absolutos. En 1979 van Rijsbergen deriva una métrica compuesta de efectividad $E$ que tiene en cuenta las métricas de precisión y cobertura [vR79]. La métrica incorpora el hecho de que los usuarios pudieran darle más importancia relativa a la precisión o a la cobertura. Esto se obtiene agregando un parámetro $\beta$ que indique que el usuario quiere darle $\beta$ veces más importancia a la cobertura que a la precisión y, por lo tanto, reflejará la relación $C/P$ para la cual el usuario está dispuesto a negociar un incremento en la precisión con un pérdida equivalente en cobertura: $$ \begin{align*} E = 1 - \frac{1}{\frac{\alpha}{P} + \frac{1 - \alpha}{C}}\text{.} \end{align*} $$Reemplazando $\alpha$ por $1/(\beta^2 + 1)$ se puede calcular la derivada parcial de $E$ respecto de la precisión e igualarla a la derivada parcial respecto de la cobertura para ver que $\beta = C / P$, como se quería. El segundo término de la ecuación es la conocida métrica $F$: $$ \begin{align*} F(P, C) &= \frac{1}{\frac{\alpha}{P} + \frac{1 - \alpha}{C}}\text{,}\\ F(P, C) &= \frac{1}{\frac{1}{(\beta^2 + 1)P}+\frac{\beta^2}{(\beta^2+1)C}}\text{,}\\ F_\beta(P, C) &= \frac{(\beta^2+1)PC}{C+\beta^{2}P}\text{.} \end{align*} $$Esta es una función $F:\mathbb{R}\times\mathbb{R}\rightarrow\mathbb{R}$ que contiene dos funciones de escala $\Phi_1$ y $\Phi_2$ para $P$ y $C$ y las combina de forma que la métrica resultante conserva el orden cualitativo de la efectividad. Como casos particulares de esta función tenemos la media armónica de precisión y cobertura, que le asigna igual importancia a ambos factores ($\beta=1$): $$ \begin{align*} F_1(P,C) = \frac{2PC}{C+P}\text{.} \end{align*} $$Otro caso particular ocurre si $\beta\to\infty$, cuando el usuario no desea asignarle importancia a la precisión, resultando en $F=C$. Por el contrario si $\beta\to 0$ entonces $F=P$. C. J. van Rijsbergen mostró también que otras métricas que ya existían en la literatura [CMK66,Hei73], eran casos especiales de la medida $E$ [vR79]. Posición Recíproca MediaLa Posición Recíproca Media (MRR) de la respuesta que produce un sistema de IR, es la inversa multiplicativa de la posición de la primera respuesta relevante en esa salida [Voo99]. Teniendo un conjunto de consultas, $Q = \{q_1, q_2, \dots, q_n\}$, se calcula el promedio de los valores obtenidos sobre sus resultados. En otras palabras, se tiene una lista ordenada de documentos, que son el resultado del sistema de IR para una consulta $q_i$ dada, se busca la posición, $\mathit{rank}$, de la primer respuesta correcta y se calcula la recíproca de ese valor. Finalmente se promedian los valores obtenidos al haber analizado todas las consultas. Esta medida se basa en el hecho de que se espera que las respuestas correctas se encuentren lo más arriba posible en la lista de resultados. Sea un función $\mathit{rank}(q)$ que devuelve la posición del primer documento relevante para $q$ devuelto por el sistema, entonces: $$ \begin{align*} \mathit{MRR}(Q) = \frac{1}{n}\sum\limits_{i=1}^{n}{\frac{1}{\mathit{rank}(q_i)}}\mbox{.} \end{align*} $$Si el sistema no logra recuperar ningún documento útil se asume que la recíproca es cero. Puede notarse que esta técnica no tiene en cuenta la cantidad de documentos relevantes recuperados. Se la ha utilizado en general en el track Question Answering de TREC en donde existen dos variantes de la métrica, de acuerdo a si se tiene en cuenta que los documentos relevantes son sólo los que responden perfectamente a la pregunta o si también se tienen en cuenta a aquellos que son acertados pero que no responden completamente a la pregunta. La primera suele llamarse MRR estricta y la segunda versión indulgente. ResumenEn este capítulo se presentaron los fundamentos metodológicos de la evaluación de sistemas de recuperación de información. Se mostraron diversas métricas de comparación, distintas colecciones de prueba y varias formas de obtener los juicios de relevancia, tres componentes fundamentales para la comparación de nuevos sistemas y nuevas técnicas de IR. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Última actualización el Lunes 16 de Septiembre de 2013 17:40 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

Caracterización Formal y Análisis Empírico de Mecanismos Incrementales de Bísqueda basados en Contexto por Carlos M. Lorenzetti se encuentra bajo una Licencia Creative Commons Atribución-NoComercial-CompartirDerivadasIgual 3.0 Unported.
Basada en una obra en bc.uns.edu.ar.